
🐹倉鼠週報17:試用 Google 的生成式搜尋引擎
這週開始感覺到非同溫層也出現了許多 AI 的新聞,是不是代表 AI 影響力又往上一層了呢?拿到了 Google 生成式搜尋引擎的試用,雖然功能還不多,但還是期待未來與 bard 的結合!


卷首語
這週看到兩個照片,讓我思考 AI 是不是真的開始進入人們視野中。過去幾個月可能只是在同溫層所以感覺 AI 影響力很大。
但紐約時報、經濟學人等重大影響力的媒體雜誌,在過去幾個月都以 AI 為封面圖,像是下面這個,這個封面著實在引起人們焦慮了。
另外一個則是在比利時安特衛普市中心的一條街道 Keyserlei 上的建築廣告。

雖然說海報上大大的寫著,建築工的技能是無可取代的,但是過去幾個月看到很多硬體上也做到技術突破,如果只是常規化的建築(或其他)工作,未來很有可能還是會被 AI + 機器給取代。
但若都有預感這是必然發生的方向了,那提前準備跟瞭解一定會比事情發生後再來懊悔來的好。
從歷史來看,自工業時代以來,自動化技術帶來的新機會一定比消滅掉的機會更多。所以適應著把部分工作交給 AI,並提高產值與改變工作型態。
比起焦慮更多的可以是期待。
進正文之前,推薦一位前輩 Vista 的新書《1分鐘驚豔ChatGPT爆款文案寫作聖經》,Vista 在寫作這個領域是超級前輩了,而且學習力超強,在思考能力及正確提問的思路非常清晰,想學如何用 ChatGPT 寫作的讀者們可以閱讀看看!
🛠️ 本週 AI 新聞 & 工具
1. 6 個使用 OpenAI API 的人都應該有的安全意識!
看到 Twitter 這個案例的主人公被盜用將近 5000 美金的 API 費用,所以起心動念寫了這篇,並在寫完後讓 ChatGPT 協助補充。

所以整理以下 6 點重要意識,可以大大保護降低自己遇到這種無妄之災的機率:
1. 🔒 不要隨意公開自己的 API 🔒
錄影、截圖或分享都可能造成 API 外流,請小心謹慎。
2. ⚠️ 設定使用上限 ⚠️

Usage Limits 可以設定軟上限跟硬上限,在觸達時會寄送 E-mail 通知,軟上限告知你達到了一定的用量,硬上限強制不能再使用 api。
設定連結:https://platform.openai.com/account/billing/limits
3. 📊 定時追蹤 API 用量 📊

這邊推薦兩款追蹤使用狀況的服務,一個是 app 一個是線上的。
Waige(快速概覽 API 用量,限 mac):https://pyrolyse.gumroad.com/l/waige
LLM Report(詳細瀏覽不同 API 使用狀況,但要提前設置好不同api及對應名稱):https://llm.report/
直接查看 API 調用紀錄:https://platform.openai.com/usage
4. 💼 使用 OpenAI 的 API 金鑰管理功能 💼
OpenAI 提供了 API 管理功能,可以輕鬆追蹤和控制每個 API 的使用情況,並即時做出調整。
API 金鑰管理設定:https://platform.openai.com/account/api-keys
5. 🚨 謹慎小心填入 API 的不同服務 🚨

這點太太太重要了,現在有很多自己寫好的服務或線上程式,你只要填入自己的 API,就能使用該服務(工具)。
但你永遠不知道該程式背後是否含有惡意,就算是上面推薦的 API 使用狀況查看工具也是。
永遠有人能把惡意行為包裝成善意服務,一旦沒有受傷的便是自己。
6. 🛡️ 確保作業系統和程式碼安全 🛡️
這點是老生常談的資料保護。
除了將 API 隱藏外,維護整體作業系統的安全也是必備的,只不過這不是只有保護 API 需要做。
確保作業系統和應用軟體都是最新版本,並經常檢查、更新程式碼來避免安全漏洞,避免將 API 儲存在易於破解的位置。
============================
總結來說需要設定的就這幾步:
1. 先設定 API 的軟硬上限
2. 為不同 API 用途設定名稱
3. 使用工具定時追蹤 API 用量
4. 最後謹慎使用
2. 10 個 Google 生成式搜尋引擎使用觀察

應該是第二批拿到 Google 生成式搜尋引擎試用的,雖然體驗下來不太滿意,對話功能不強而且會有亂說話的情況發生,還不確定會怎麼與 Bard 整合。
但我還是期待後續陸續新增/強化的功能,而且現在 Google 也在開發另一套名為 Magi 的搜尋引擎。
保持關注!以下是相關畫面。
一般對話:
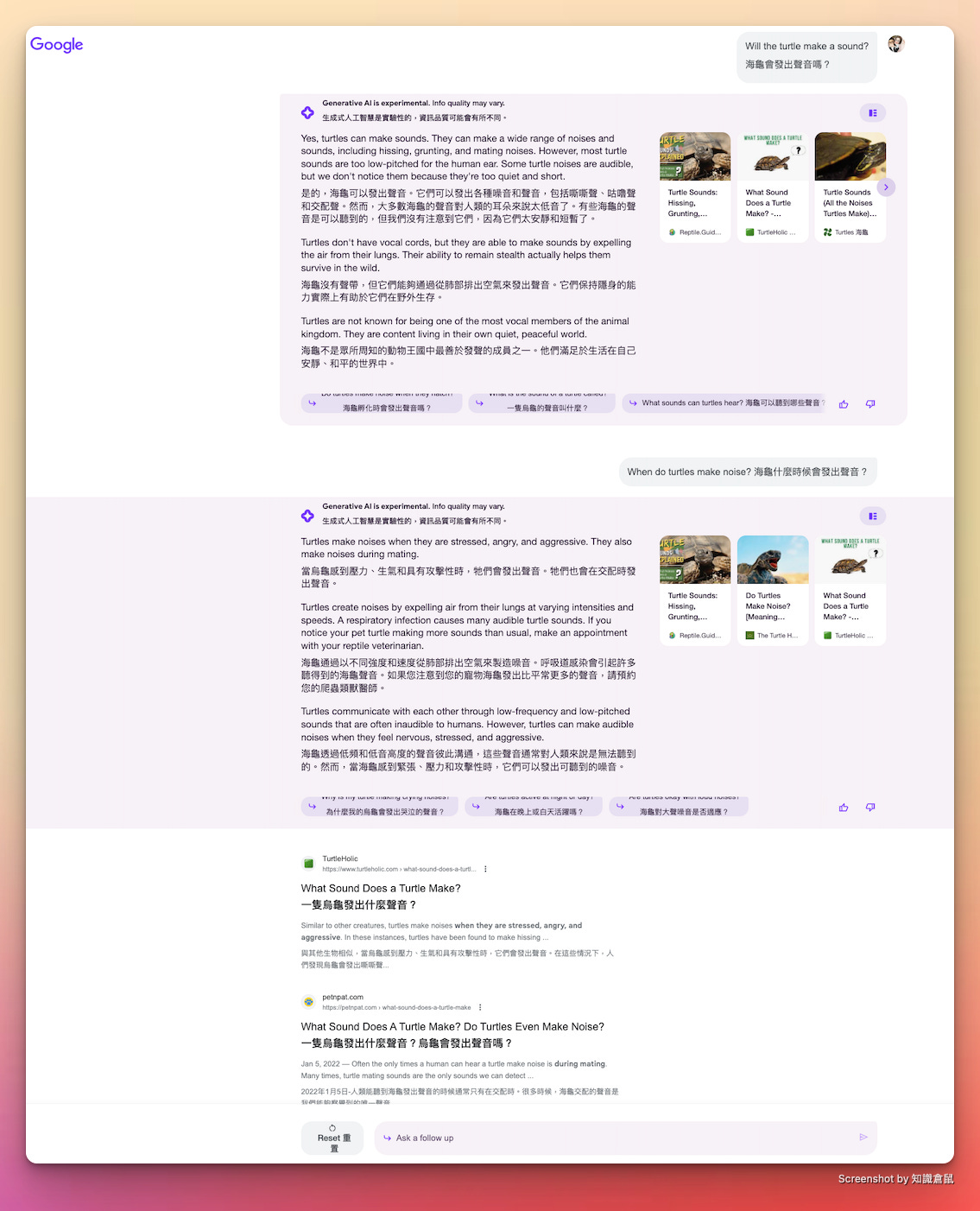
連續問答主要參考搜尋結果第一頁為主,看不到第二頁以後的結果。
我擔心的是以後怎麼計算追蹤這些數據
還是會亂說話,請勿盡信

目前精選摘要與 AI 整合的答案同時存在

結合不同來源的內容形成觀點
地區相關問答會以 Local Search 為主

Google 會重新分解問題變成適合的關鍵字進行搜尋

可以寫程式但沒辦法 Debug,會直接給你錯誤訊息的搜尋結果,這點不如用 ChatGPT。

快速查看體驗後的感想:
Google 會將問答先拆解成適合的搜尋意圖,再進行搜尋統合資訊
可以展開整合資訊便知道不同區塊回答的來源 - 目前看起來 SGE 像是強化版的精選摘要,對話能力不強
生成式問答 = AI 整理回答 + Google 第一頁搜尋結果
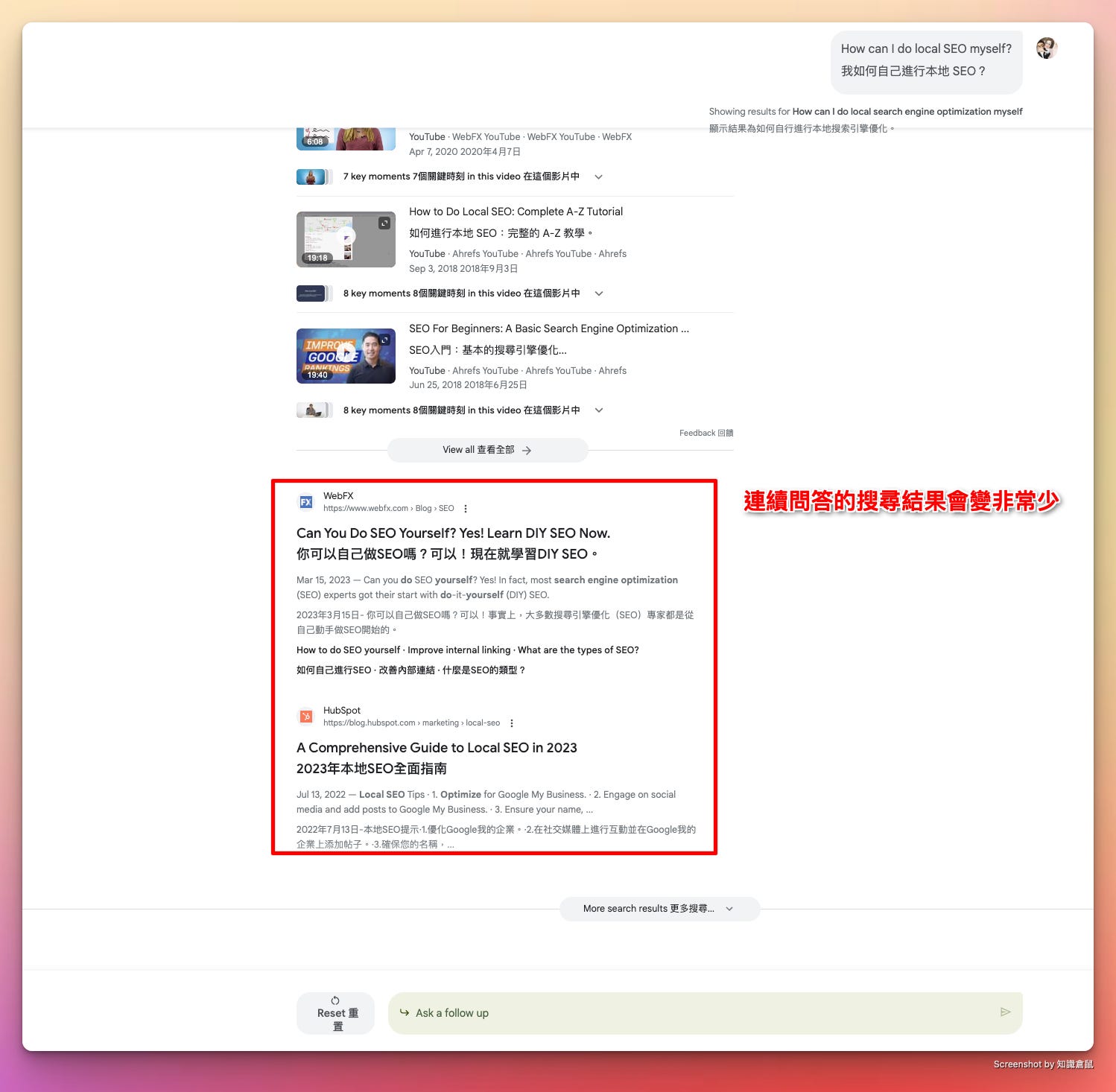
其它參考資料只會有第一頁的結果,看不到第二頁
與地區字有關的內容會抓取 Local Search 的結果進行整合
幻覺(亂說話)現象依舊可能發生
精選摘要目前會同時與 AI 問答同時存在
可以寫程式但不能 Debug,會直接返回搜尋要自己查
資料調查時,可以將不錯的搜尋結果直接儲存到 Google Sheet 中



3. 優質 AI 課:吳恩達又來啦,重磅 3 堂課,限時免費

一樣是跟 OpenAI 合作開課,雖然主要是給開發者的課程,但是課程說明有提到只要有 Python 基礎就可以學了。
這三門課分別是(各 1 小時而已):
建立與 ChatGPT API 相關的系統
使用 LangChain 進行 LLM 開發
Diffusion 的運作原理
想學用 LangChain 的朋友真的推薦一看!
課程總覽: https://www.deeplearning.ai/short-courses/
Building Systems with the ChatGPT API: https://www.deeplearning.ai/short-courses/building-systems-with-chatgpt/
LangChain for LLM Application Development: https://www.deeplearning.ai/short-courses/langchain-for-llm-application-development/
How Diffusion Models WorkL: https://www.deeplearning.ai/short-courses/how-diffusion-models-work/
中文版:
使用ChatGPT API建構系統:https://www.youtube.com/playlist?list=PLiuLMb-dLdWKjX8ib9PhlCIx1jKMNxMpy
擴散模型是如何運作的(更新中):https://www.youtube.com/playlist?list=PLiuLMb-dLdWKh6Oq46LZ3pLwlmYuMYl_g
4. 用 GPT-4 分析 Twitter 演算法,並制定爆文策略
給了 GPT-4 Twitter 在 GitHub 上釋出的 feed 演算法,用 browsing 的功能。
可以看到 GPT-4 會有『閱讀』、『思考』、『返回上一頁再閱讀』、『尋找其它資訊』,然後再總結。 Browsing 功能在思考及蒐集資訊上比其它 Plugin 還強大,所以還是蠻值得一用的!
這篇 prompt 調了好久,結果也重新產生很多次,並不是一次到位,但結合了原理的策略讓我更明白怎麼調整發文策略。 希望之後在 twitter 上的貼文可以不斷成長!
以下是調整並再整理後的內容。
▎Twitter 演算法組成
Twitter 的推薦算法每天將約五億條的推文篩選出幾條最佳推文,最終在你的設備上顯示「為你推薦」的 feed。
推薦系統由許多互相連接的服務和任務組成,Twitter 的推薦系統透過分析大量的數據,試圖理解 Twitter 網絡的結構和動態,以便夠更有效地向用戶推薦他們可能會感興趣的推文。
負責構建和提供「為你推薦」feed 的服務稱為「Home Mixer」。
Home Mixer 基於 Twitter 自定義的框架「Product Mixer」構建,該框架能夠方便地建立內容來源,並將不同的『候選人來源』、『排名』、『啟發法和過濾器』3 者連接起來。
以下是推薦管道的三個階段介紹:
▎1. 候選人來源(Candidate Sourcing)
就像是在巨大的圖書館中找出你可能感興趣的書籍。
Twitter 從你所關注的人(In-Network)和你未關注的人(Out-of-Network)中找出最近的和最相關的推文作為候選人。
這一階段的目標是從數以百萬計的推文中挑選出最佳的 1500 條推文。
目前,「為你推薦」feed 平均由 50% 的 In-Network 推文和 50% 的 Out-of-Network 推文組成,但這可能因用戶而異。
尋找用戶網絡之外的相關推文是一個比較棘手的問題:如果你沒有追蹤某個推文的作者,我們怎麼知道這條推文對你來說是否相關?
Twitter採取了兩種方法來解決這個問題:
分析你追蹤的人或有相似興趣的人的互動,來估計你可能會找到哪些內容相關。
利用 Embedding space 方法來找『哪些推文和用戶與我的興趣相似?』
▎2. 排名(Ranking)
就像是對圖書館中的書籍進行評分,決定哪些書籍最可能吸引你的注意。
Twitter 使用一個包含約 4800 萬參數的神經網路模型來評估每條推文的相關性,並根據評分對推文進行排序。
▎3. 啟發法和過濾器(Heuristics and Filters)
就像是在準備閱讀這些書籍之前,根據你的偏好來過濾和整理書籍。
這一階段的目標是建立平衡且多樣化的推文來源,例如:
過濾掉你封鎖或靜音的帳號的推文
避免連續顯示來自同一個作者的太多推文
確保提供適當的 In-Network 和 Out-of-Network 推文的平衡
並確保你關注的人與推文或推文的作者有關聯
以上的步驟每天運行約 50 億次,平均在 1.5 秒內完成。
單次管道執行需要 220 秒的 CPU 時間,這幾乎是你在應用程式上感知到延遲的 150 倍。
▎如何在Twitter上更有效地發布推文,以下是 6 個策略:
提高用戶互動:
由於 Twitter 的算法使用 Real Graph 模型來預測兩個用戶之間的互動可能性,所以提高用戶互動是非常重要的。
透過發表能引起人興趣的內容,並積極與你的追蹤者互動,來提高 Real Graph 分數。
這樣推文更有可能被呈現在你追蹤者的 feed 中。
創建與現有社群相關的內容:
Twitter 的 SimClusters 模型會找到由影響力用戶錨定的社群,並將用戶和推文推薦到這些社群中。
因此,建立與目標社群相關的內容可以提高推文在這些社群中的相關性,並增加它們被推薦給社群成員的可能性。
鼓勵第二度連接互動:
Twitter 的過濾器會排除沒有第二度連接的 Out-of-Network 推文。
也就是說,如果你的推文沒有被你的追蹤者或他們關注的人互動,它就不太可能被推薦給其他用戶。
因此,鼓勵你的追蹤者和他們的追蹤者互動可以增加推文的曝光機會。
使用趨勢主題和標籤:
Twitter 的一部分演算法工作是找出正在社區中流行的推文。
如果你的推文與當前流行的主題或標籤相關,它可能更容易被推薦給那些對該主題或標籤有興趣的使用者。
因此,使用趨勢主題和標籤並建立相關內容可以是一種有效的策略。
與影響力大的使用者互動:
Twitter 的推薦演算法會考慮你和其他使用者之間的互動。
與影響力大的使用者互動,例如回應他們的推文或提到他們,可能會提高你的推文在他們的追蹤者中的可見性。
此外,這種互動可能會增加你與這些使用者的 Real Graph 分數,進一步提高推文的可見性。
適當地更新推文:
Twitter 的過濾器會檢查推文是否已經過時。
這意味著,如果推文需要更新你應該立即進行,確保它在 feed 上的可見性。
而且定期更新推文也可以顯示你對內容的熱情和參與度,有機會吸引更多的互動。
===
以下是 prompt: 『請你作為一名專業的技術人員及行銷人員,分析給定連結的twitter演算法,用大學生也能聽懂的比喻詳細解釋原理與專有名詞。並根據該原理,給出獨特的貼文策略(並說明與哪個演算法相關),能在twitter上達到高互動、高分分享、高轉發等病毒式傳播的行為。https://github.com/twitter/the-algorithm』
===
5. RealityGPT:AI 結合可穿戴裝置
史丹福大學的一名學生 Joseph Semrai Demo 了 AI 與穿搭設備結合的場景應用。
RealityGPT 主打『全球首款能給你 ✨ 完美記憶 ✨ 的可穿戴裝置』,並給出四個重要應用場景。
🧠 永遠不會忘記任何活動細節。
🤖 在現實世界中使用人工智慧。
🌎 從網路上即時取得資訊。
🗣️ 能說任何語言
目前還比較少看到將 AI 在實體場景上的相關應用,雖然會有人覺得這只是 Demo實際效果一點都不好。
可是不是正因為有了想像,才能實現一切可能嗎?期待後續發展!
來源:https://twitter.com/josephsemrai/status/1664764918275375105