
🐹倉鼠週報22:突破天際的token上限開啟更多想像
這週分享了一些 ChatGPT 使用上的眉角,Plugin 還是很值得開發不同玩法的,不只是用來優化自己的工作流程,更是為了增強未來如何透過自然語言與 AI 進行溝通。


卷首語
這週連續看到兩個 Token 上限突破的論文及應用,十分期待成熟的時候,目前部分技術瓶頸都卡在上下文數量,一旦突破了很多工具就能往上突破一個層次。
很多人都說 Code Interpreter 釋出了很興奮,這是一個很逆天的功能。可是對於大多數人來說,有強大的武器但不知道怎麼使用可能是目前最頭痛的現況。
AI 不是只有在軟體上的應用,這週也分享了實體技術的應用,軟體與實體產業的結合將是帶動生產力感受最直接的衝擊。
Plugin 的玩法還是非常多變,大家千萬不要忽略多研究一些玩法,這也是在強化與 AI 溝通的能力!
🛠️ 本週 AI 新聞 & 工具
1. 請 ChatGPT 根據論文寫研究電子書(續)

延伸上週的內容,然後整理了一些自己踩過的坑,因為上週中文一直翻譯失敗。
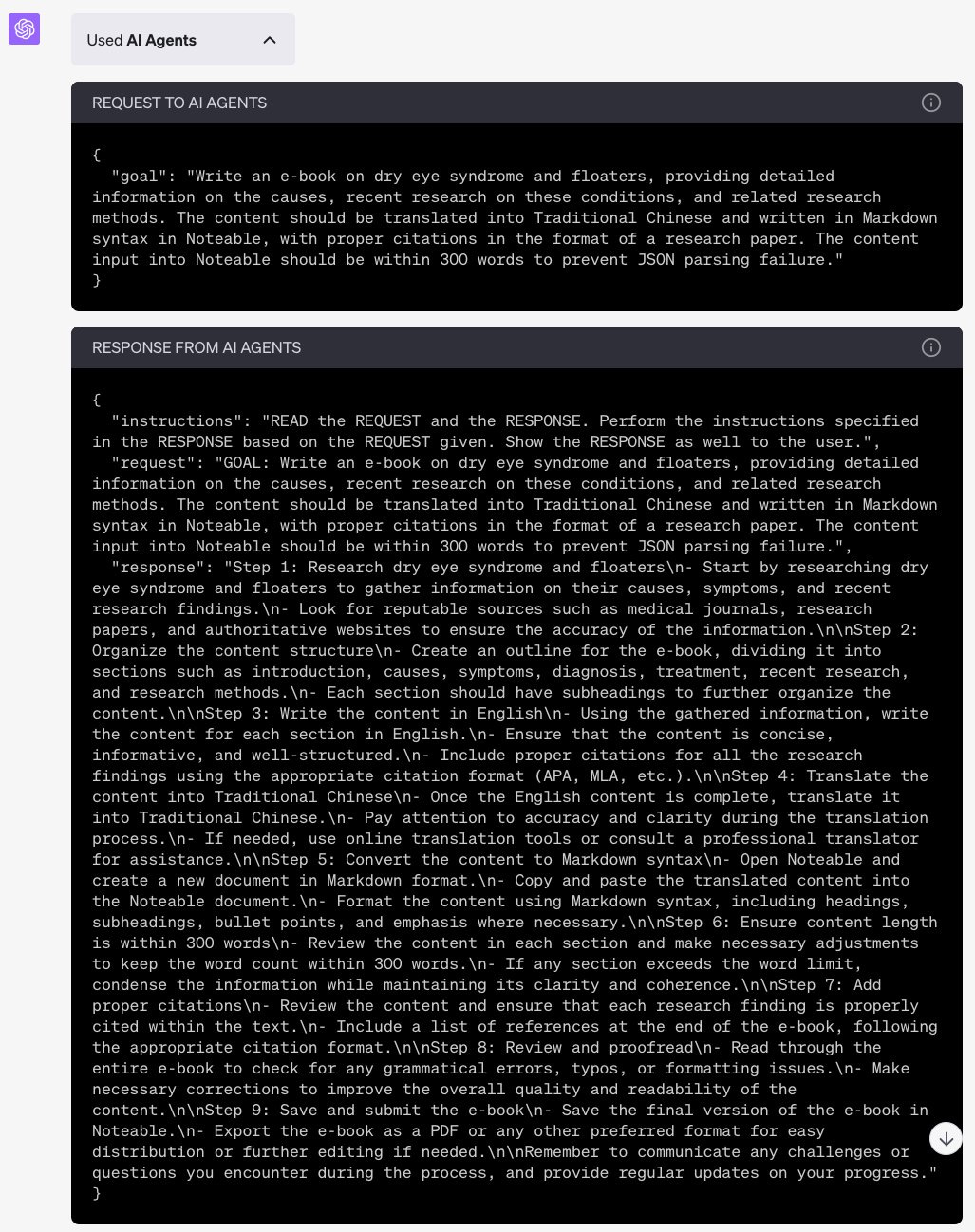
我感覺用 AI Agent,除了它會詳細的幫你分解任務外,還會把任務目標以 json 的格式儲存在另一處,不讓 ChatGPT 遺忘目標。 但這是我猜的,主要是因為用這個 plugin 比較少出現上下文過長而遺忘的狀況。
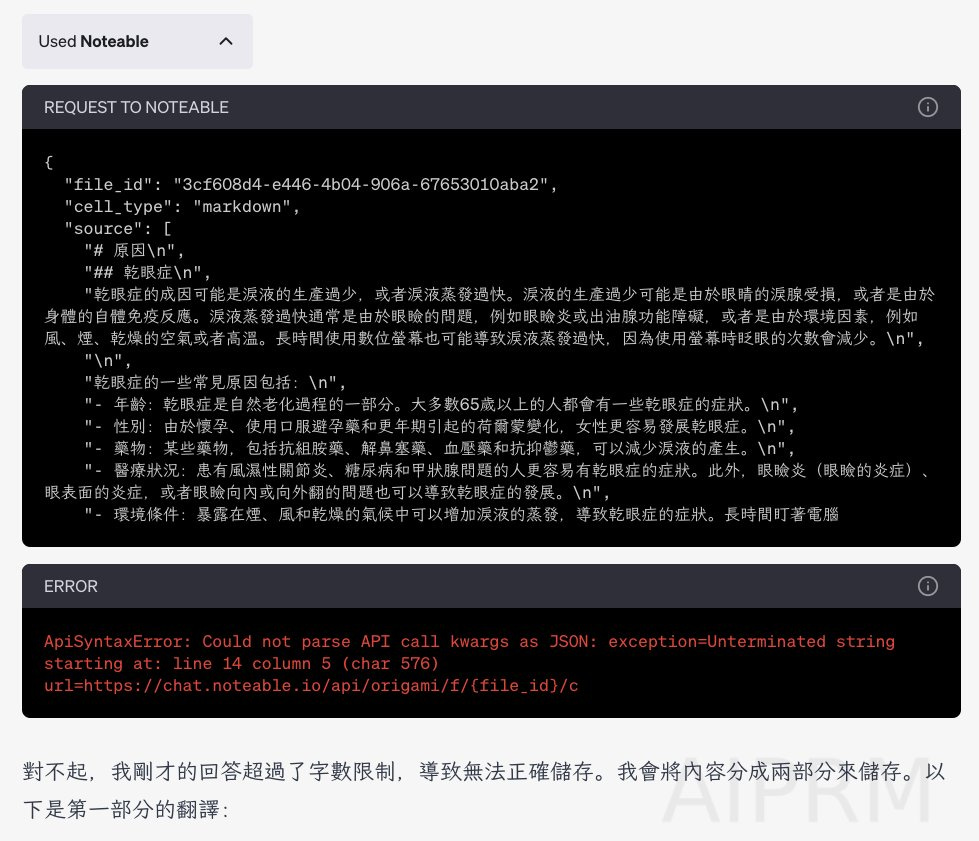
每次看到 ChatGPT 在調用 Plugin 時,一定要注意 REQUEST 及 RESPONSE,看了才知道有沒有出錯,非常重要。 然後針對錯誤去找不同的解決方式。
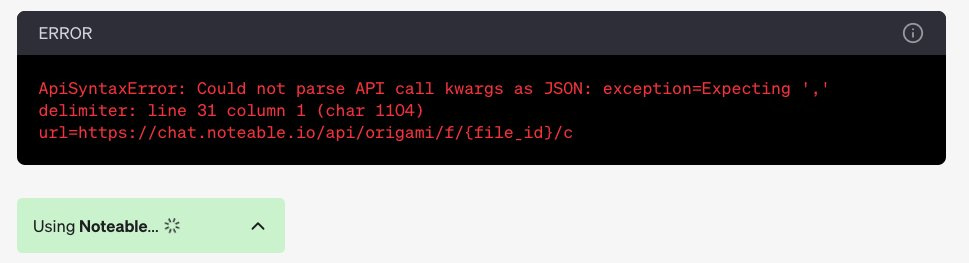
noteable 要用中文寫入一定要減少寫入每個 cell 的字數。因為 ChatGPT 的 Plugin Noteable 每個 cell 有輸入上限,中文很容易導致超過上限,結果結尾處沒有正確結束。
加這一句來解決該問題:『請減少每次輸入 noteable 的內容在 300 字內,確保參數能正確結束,不要導致 JSON 解析失敗。一旦寫入失敗將寫入內容減少,未完成的內容可以透過下一輪對話輸入。』
.
使用調查資料用的 Plugin,像是 scholarAI,一定要記得用上這個 prompt:『Search in English.』或是『Search in English and return in Traditional Chinese.』 英文搜尋結果會比中文好上太多太多。
.
最好內容也能先用英文寫完,最後再翻譯成中文。 我自己實驗下來發現,請 ChatGPT 整理資料後直接寫成中文效果並沒有先寫成英文後翻譯好。
.

如果寫完完整英文內容,但內容也蠻長的話,可以用這個 prompt(試了好幾次覺得效果比較好也比較不會出現幻覺的):
『AI agent 目標:請你先重新讀取一遍英文內容,每次都先在 ChatGPT 這邊翻譯給我看後,再儲存到另外一個 notebook 上,每翻譯完一個小節就寫入 noteable。』 但切記還是要隨時檢查內容有沒有脫軌!
對話:https://chat.openai.com/share/5cdff67d-2860-477b-aaa9-6ae146fb2809
中英文的研究電子書:https://bit.ly/3rm6X4X
2. 10 億 token 是什麼概念!

這是微軟最新一篇論文,研究中將 token 數直接拉滿到 10 億。
Claude 的上下文 token 是 100,000,大概一本《哈利波特》,約 75,000 個單字。
微軟這次研究這個是 1,000,000,000 個 token,1 萬本哈利波特了。
論文中比較重要的部分在於,提出了一個新的研究叫 LONGNET,是 Transformer 的一種變體。
而其中的核心在於一個注意力機制的變體『dilated attention』。
LONGNET 有 3 個優勢:
計算複雜度是以線性計算
可以作為一個極長序列的分佈式訓練器
dilated attention 可以無縫接軌原有的標準注意力機制,與現有基於 Transformer 的優化方法無縫整合
現在讓我來把它翻譯成一般人也看得懂的語言,Let's go !
▎先說 dilated attention(擴張注意力)
dilated attention 是注意力機制的一種變體。
在原始的注意力機制中,模型會對所有的輸入詞語分配注意力分數,並根據這些分數來決定應該關注哪些詞語。
但是這種方法在處理非常長的序列時可能會有困難,因為模型需要計算和存儲所有詞語之間的關係,在序列非常長時會非常耗時和佔用大量記憶體。
dilated attention 就是為了解決這個問題而提出的。
在 dilated attention 中,模型不再對所有的詞語分配注意力分數,而是只關注到一部分"重要"的詞語。
這些"重要"的詞語是通過 "dilation" 的技術來選擇的,這種技術可以讓模型的感知範圍隨著距離的增加而指數級擴大。
這種方法的優點是,可以大大減少計算和存儲需求,使模型能夠處理非常長的序列。
同時由於它只關注到一部分"重要"的詞語,所以它仍然能夠捕捉到序列中的重要信息,並保持良好的成效。
接著解釋 3 大優勢:
▎1. 計算複雜度是以線性計算

一般來說,計算複雜度很容易隨著問題成長而呈現指數成長。
所以線性計算複雜性是一個重要優勢,因為它意味著處理時間或者計算資源與問題的大小(這裡指序列的長度)成正比。
換句話說,如果序列長度加倍,那麼處理它所需的時間或計算資源也只會加倍。這是非常有效率的方式,特別是對於非常大的問題。
相對的,如果一個問題的計算複雜性是二次的,那麼當問題大小加倍時,所需的計算資源會變成原來的四倍。如果是立方的計算複雜性,那麼問題大小加倍時,所需的計算資源會變成原來的八倍。這樣的計算複雜性對於大問題來說是非常低效的。
▎2. 可以作為一個極長序列的分佈式訓練器

想像一下,你有一個非常長的數學問題需要解決,但是這個問題太長,一個人無法在合理的時間內完成。
於是你把這個問題分成了很多小部分,並讓你的朋友們各自解決一部分。
然後,把所有人的答案組合在一起,得到了最終的解答。
這就是分佈式訓練的概念,LongNet 可以將一個非常長的序列分成多個部分,並且在多個計算單元上同時進行訓練。
▎3. dilated attention 可以無縫接軌原有的標準注意力機制,與現有基於 Transformer 的優化方法無縫整合
這就像是你有一個老式的電視,但是你想要升級到一個新的、更大的螢幕。
你不需要更換所有的設備,只需要將新的螢幕接入你現有的設備就可以了。
同樣地,我們可以將原本的注意力機制換成 dilated attention,這種替換不會影響到那些已經存在的、用來優化 Transformer 模型的方法,這些優化方法仍然可以正常運作。
.
大容量的上下文已經是一個趨勢了,但這麼大的上下文應該主要還是特定場景為主。
另外在長上下文之下,幻覺(胡言亂語)也會變的非常少,如何調用所需來創造新事物就會是另一個個人必備能力。
萬維剛曾說過『創造就是想法的連結』,目前 LLM 調用能力強,但連結創造的能力還不強(至少目前看來)。
已經迫不及待想用上超長上下文功能的 LLM 了。
論文:https://arxiv.org/pdf/2307.02486.pdf
github:https://github.com/microsoft/unilm/tree/master
3. AI 開發的革命!?
上一篇分享微軟的 10 億 token 論文,現在市場上出現了一個上限 500 萬 token 的語言模型「LTM-1」。
也許未來維護大型專案或網站真的就能靠 AI 來維護及增減功能,『如何與 AI 溝通來實現網站功能』會是個人必備能力之一。
由新創公司 Magic (A 輪融資 2300 萬美)所開發一種名為長期記憶網路(LTM Net)的新方法。
相比 GPT-4 的 3.2 萬 token,足足是 50 倍。
相當於 50 萬行程式碼和 5000 個檔案,能完全覆蓋大部分的程式庫。
而且能夠批次進行重構,讓錯誤修復和維護工作瞬間完成,還能在不同檔案之間重新使用和合成資訊。
雖然目前還需要排 Waitlist,不知道效果如何,但既然出現了這樣的產品,市場也確實有這樣的需求。
透過 AI 改變未來的開發模式就是必然的趨勢。
4. AI 農業:雷射燃燒除草
現在每天都是電腦上的 AI,偶爾來看看實體世界的 AI 應用。
這個是由機器人公司 Carbon Robotics 推出的第三代自動除草機器人。
這種技術不僅不會破壞土壤,還可以避免農藥,每小時可以消滅掉 10 萬株雜草。
對於執行的人力成本效率更是提升非常多。
自主除草機能夠每小時除去超過 10 萬株雜草,每天的作業範圍約為 15 至 20 英畝(約 61,000 至 81,000 平方米)。
而人類每天能夠除草的面積大約為 4,000 平方米左右。
自動除草機是不使用化學物質的除草工具,已獲得華盛頓州農業局(WSDA)的「有機」認證!
另外在 Twitter 上也看到一個用圖像識別來摘果子的影片,特別有趣。
完整影片介紹:
5. ChatGPT 的 Code Interpreter 開放使用

設定 > Beta Feature > Code interpreter 打開(限 Plus 用戶)
簡單來說,Code Interpreter 就是一個可以用 Python 功能的聊天機器人,被關在一個封閉的環境中,不能連上網,但是可以上傳檔案處理後並下載。
因為可以寫程式,所以請它透過程式來分析資料、做資訊圖表、編輯影片等功能,讓原本只能對話的功能變的非常強大。
至於為什麼不能連網,試想一下如果它能連網然後自己寫個程式轉移自己出去豈不可怕,所以 OpenAI 必須做好準備才能讓它嘗試連上網。
目前可以用的功能非常多,想像力就是你的超能力,備用的最多的應該會在數據分析上,所以也需要一些數據分析的基礎知識。
但這兩天看到的使用案例都是”玩玩”居多,最近會多收集一點按理,分享這些玩玩的案例對大家使用幫助並不大,有興趣可以看 Ethan 的 Twitter 非常完整。
也歡迎大家分享自己的用法來討論!