
調校 AI Skill 的七個血淚經驗:從燒錢到穩定跑的實戰筆記
提煉好讓 AI 可以複用的技能,是讓 AI 可以跟你深度合作的關鍵!


卷首語:
有些新朋友應該第一次看到這個發信,感謝很多 substack 上的優質電子報們有推薦知識倉鼠,所以你們才會在訂閱他們的電子報時,也一起訂閱了知識倉鼠電子報。
最近把我的倉鼠 AI 調教好了,再來會讓他整理各種好文到『倉鼠好文解讀』區塊,牠也會分享自己的心得喔!
今年最重要的東西之一就是 Skill 了,非工程師的人不用急著研究 Harness 系統,可以把自己的經驗提煉成 AI 也能用的 Skill 才是最重要的。所以今年大家會一直聽我推 Skill 🤣。
去年年底老婆的手運動受傷,所以今年年初開刀,行動很不便,日常也需要更多時間陪伴協助。大家平常要多留意自己身體呀,每次受傷都可能需要很久才能復原,事前保護好很重要!
最近在做一件事,把各種 AI 助理都串到 Discord 上,未來要讓 DC 真的能變 AI 組織溝通的一個平台,不過坑很多,怎麼做公司知識管理等等的都必須好好想一下,這個 Skill 只是第一步,未來會在電子報持續分享,也歡迎大家聊聊!
這次倉鼠圖的風格我有夠喜翻的,該自寶玉的提示詞。
想要第一手跟大家討論 AI 跟應用歡迎加入知識倉鼠社群喔!
================= 廣告時間 ================
📣 用 AI 卡關的,從來不是 AI
你有沒有遇過一種情況,就是你叫 AI 改一個地方,它順手改了另外三個。
而你發現的時候,已經是兩週後。
你用 AI 寫過小工具。最後通常是這樣收場:跑了兩週突然壞掉,找半天找不出哪裡出問題。
或是這樣:你滿懷期待,叫它加個新功能。它順手把舊的也改了。你叫它修。冒出新 bug。你忍痛叫它重來。換了個寫法,同樣問題。
這個迴圈,你跑過幾次?
這不是你不會用 AI。是沒人教你怎麼讓 AI「按規矩做事」。
林鼎淵老師在課程說明會講了一句話,把這件事說得很清楚
「最可怕的不是 AI 把功能改壞,而是你不知道它把正常的功能改壞了。」
你那個「上禮拜明明可以、今天又不行」的感覺,就是這句話。
用 AI 做東西最常卡的三件事:
穩定性:改一個地方,過去做好的東西跟著爆
複雜度:功能一多,你根本沒空把每條操作路徑走過一遍
擴充性:沒寫清楚規格,每次加新東西都在踩雷
這些問題本來就存在。只是 AI 寫得太快,把後座力放大了好幾倍。
這堂課跟市面上「ChatGPT / Claude 教學」最不一樣的地方
最近 TibaMe 找我合作推林鼎淵老師的新課《Claude AI 驅動全端開發工作流》,9 小時的直播實戰課。
我先看了 1.5 小時的課程說明會錄影,老師有兩個立場特別讓我點頭。
◆ 老師不是在教 prompt 技巧
社群上看過太多「下對指令、AI 就會幫你做出系統」的影片。
但你真的做過就知道:哪有那麼簡單。
真正的關鍵不是更聰明的 prompt,是把整條工作流建立起來。從怎麼寫需求、怎麼讓 AI 不亂改、怎麼自動把關品質,到怎麼同時處理多個任務不互相打架。這 9 小時的課把整條串起來。
◆ 老師反對「同時開一堆 AI 一起跑」
社群媒體很流行「開五個視窗讓 AI 一起做事」的畫面。
老師直接說:
「一堆 AI 同時執行,問題不一定能解決,但 Token 消耗絕對是真的快。」
他的立場很單純:對自己手上專案的掌握度,比什麼都重要。
老師有句話我抄下來貼在記事本:
「好的結果不應該是靠消耗 Token 拼運氣,而是靠清楚的方向、可重複的工作流,以及人類在關鍵節點上做出來的決策。」
建立起這條工作流之後,你會變成什麼樣子

先把需求講清楚,再讓 AI 動手。 不必跟它來回對話 20 次才寫對。
設好自動把關的關卡。 AI 寫出不符合規矩的東西,根本進不到下一步。
把你的工作習慣存成「可重用的技能包」。 不必每次都重新教 AI 同樣的事。
同時處理三件事不打架。 新功能、別人請你看的東西、要修的 bug,各走各的軌道。
這不是科幻。是把 AI 從「不穩定的工具」變成「可重複工作流」的差距。
幾個我覺得很實戰的設計
自動化品質關卡 老師原話:「格式檢查、自動測試這種事,是 100% 必然會做的,那就不需要交給 AI。」AI 不穩,但流程穩。
用 OpenSpec 寫規格、用 Agent Skills 客製化你的 AI 工具 網路上現成的 Skills 不見得符合你的工作習慣。課程教你針對自己的需求做客製化,把工作流程變成可重用的資產。
多任務切換不打架(Git Worktree) 老師有特別澄清過,這個工具不是為了「同時開十個 AI」。而是為了你真實的工作情境:同時處理新功能 + 別人請你看的內容 + 要修的 bug。
自動檢查 + 權限把關 即使你不是工程師,也能提出修改建議,但要由有權限的人確認後才會生效。很適合小團隊讓非工程角色一起參與 AI 開發。
自動化測試是「玩具走向產品」的關鍵 老師原話。覆蓋率不重要,重要邏輯有沒有被驗證才重要。
這堂課適合誰
用過 ChatGPT / Claude / Cursor 寫東西,但常被它改壞舊功能搞到崩潰的人
想從「叫 AI 寫單檔小工具」進化到「讓 AI 穩定做出一整套系統」的人
想把自己的工作流程「自動化 + 可重複」,不要每次重新跟 AI 對齊的人
PM、技術主管、自由工作者、創業者:老師說過去曾教過完全零工程背景的 HR,最後也都做出系統
不適合誰
想學一招 prompt 技巧就解決所有問題的人(這堂是 9 小時系統課)
完全沒摸過 AI 工具、也沒寫過任何程式的純小白(建議先用過 Claude Code 或 Cursor、有基本檔案版本管理概念)
課程資訊
課程名稱:Claude AI 驅動全端開發工作流|導入 Agent Skills 提升開發品質與效率
講師:林鼎淵(外商全端工程師、超過 100 場企業內訓、出版過 7 本書)
形式:3 次直播實戰 + 永久回放(共 9 小時)
時間:5/30、6/6、6/13 週六 13:30–16:30
課後產出:完整全端系統 + 自己客製的 AI 工具庫 + 完整的規格文件 + 自動化品質檢查機制
🎟️ 專屬折扣碼:JOON(全大寫)→ 折 NT$1,000 元
🔗 課程頁:https://tibame.tw/QIjhU
「工具會過時,框架會淘汰,但解決問題的思維永遠有價值。」 —— 林鼎淵

=============== 廣告時間結束 ==============
為什麼你一直在改 Skill,但永遠改不好?
你對 AI 說:「幫我建立一個筆記 Skill。」
它花了三十秒,產出一個 800 行的 Prompt,塞在錯誤的資料夾,路徑錯了,變成你再也找不到的幽靈檔案。
你再說:「這不是我想要的,請修改。」
它又花了三十秒,產出另一個 800 行。這一次結構跟上一個完全不一樣,但同樣不是你想要的。你嘆氣,它也彷彿嘆氣。
這個場景,開發者叫它「Prompt 輪迴」。

背後的原因很簡單:你在對 AI 許願,但沒有告訴它「怎麼許」。
以下七個原則,是我燒了不知道多少 API 費用之後,歸納出來的實戰經驗。每一條都有一個核心觀念,我會用中學生也能聽懂的方式解釋,也會在關鍵地方放正反對比範例,讓你知道「這樣做是對的,這樣做會出問題」。
原則一:目標要像食譜,不要像減肥標語

先做一個思想實驗。
你要教一個從來沒有做過菜的人煮紅燒肉。
你說「做出美味的紅燒肉」,他端出糖醋排骨。
你說「做一道不加醬油、甜度來自冰糖、三層肉要先過水去腥的紅燒肉」,他端出來的起碼是紅燒肉,頂多甜了一點或淡了一點。
「美味」是減肥標語,「不加醬油」是食譜。
AI 也是一樣。你說「幫我把筆記整理好」,它可能把你的筆記整理成一篇心靈雞湯。但如果你說「請用以下格式輸出三個要點:每個要點包含標籤、主題句子、不超過五十字的說明。請參考 references/format-example.md 的結構」,出來的東西起碼在軌道上。
反面的 Prompt:
請幫我總結這篇文章的重點。正面的 Prompt:
請提取文章中的三個核心概念,並強制以 JSON 格式輸出,
包含 concept_name(概念名稱)和 explanation(三十字以內的解釋)兩個欄位。
請參考 references/ 資料夾中的 format_example.json。兩個 Prompt 說的是同一件事,但後者給了 AI 三樣東西:要幾個(3 個)、輸出格式(JSON)、參考範本(format_example.json)。目標越能量化,AI 越不需要猜。
實務上怎麼累積「好範本」?把你的舊文章、你認為寫得好的筆記,分類放進 references/ 資料夾。這個資料夾是 AI 的「口味參考書」,它讀了就知道你喜歡什麼風格,不需要你每次都重新形容一次。
原則二:讓 AI 的思考過程像直播,不是黑盒子
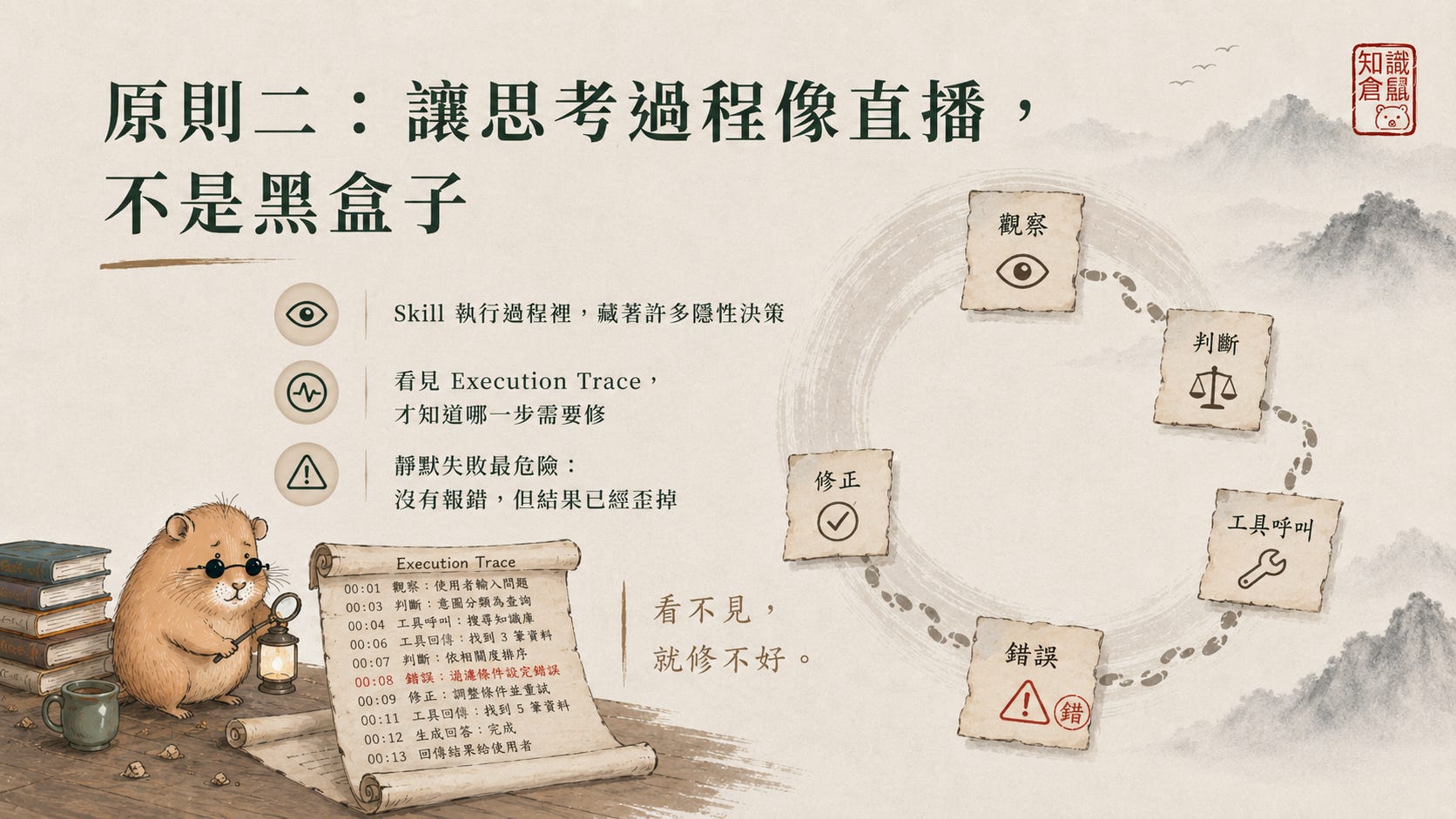
有一天,網路上流傳一個關於馬雲的都市傳說:他跟秘書說「幫我買個肯德基」,秘書直接把整個肯德基買下來了。
這當然是笑話,但笑點背後藏著一個真問題:你根本不知道秘書在想什麼。
AI 也會這樣。每一個任務的中間,都充滿了隱性決策:什麼該先做、什麼可以省略、什麼時候該重試、什麼資訊可以忽略。這些決定都是 AI 自己做的,你看不到,所以沒辦法糾正。
看不見,就沒辦法修。
這就是「執行鏈路」(Execution Trace)重要的原因。
我自己開發了一個 session observer 工具,不是 Hermes Agent 內建的功能,但概念適用於任何 Agent 系統。它的功能是:把 AI 執行任務的過程,像直播一樣逐步攤開給你看。每一個來回的前 50 個字是什麼、哪一步呼叫了工具、哪一步出現錯誤,你全部看得見。
當你能看見「第三步噴錯誤了」,你就可以回去檢查第三步的 prompt 或工具是不是有問題。而不是對著整個失敗的結果發呆,不知道從何修起。
一個很重要的觀念:靜默失敗(Silent Failure)。
傳統軟體出錯,電腦會直接跟你說「Error」或直接當掉。但 AI 的執行環境不是這樣的。AI 有時候 API 回傳 200 OK,程式碼也沒有報錯,但結果卻是「一本正經地胡說八道」。
這種錯誤沒有任何訊號,就像一個人點頭說「收到」但其實完全做錯了。因為沒有語法錯誤,所以普通工程師的除錯方法(斷點偵錯之類的)完全派不上用場。你只能靠「追蹤軌跡」(Tracing)來還原 AI 在哪一步想歪了。
這也是為什麼「看見執行鏈路」這件事,在 AI 時代比傳統程式設計更重要。
原則三:錯誤訊息要像醫生問診,不要只說「你生病了」

假設你去醫院做檢查,拿到報告,上面只寫六個字:「健康檢查異常」。
你會不會想把報告撕掉?
不好的指令碼就是這種教練。你叫它執行圖片生成,它回你「Error: 429」。你只知道「有問題」,但不知道是什麼問題。是餘額不足?是 API 速限到了?是引數傳錯了?還是那段程式碼壓根沒被執行到?
好的指令碼會說:「429 insufficient_quota 錯誤。目前有兩種可能:第一,API 餘額不足;第二,同一時間送出的 requests 太多,觸發速限。建議下一步:開啟 API 後臺確認餘額,或查閱官方檔案確認速限設定。」
這句話厲害在哪裡?它同時告訴你三件事:問題是什麼(429 insufficient_quota)、可能原因(兩種)、下一步行動(查餘額或查檔案)。
不好的指令碼回應:
Error: 429好的指令碼回應:
[錯誤] 429 insufficient_quota
[原因] (1) API 餘額不足 (2) 觸發速限
[建議下一步] 請確認餘額或查閱 API 檔案設計 Skill 裡的工具指令碼時,想像你是帶一個菜鳥實習生。他不會讀空氣,你不給他明確的指示,他就站在那邊不動,或是做出完全預期外的行為。
一句有用的錯誤訊息,等於一張清楚的地圖,告訴 AI 下一步該往哪裡走。
原則四:先看全景,再深入細節

你有沒有過這個經驗:開啟一張地圖,它預設顯示的是你家方圓十公尺的街道圖,然後你完全不確定自己在哪裡、地圖外的世界長什麼樣。
這就是直接把 40 萬 token 的 session 全部展開給你看時會發生的情況。
正確的做法是「漸進式披露」:
先看全景圖。你可以看到整個執行的輪廓:第一步用了什麼工具、第二步失敗了、第五步恢復了。用 session observer 工具,你可以先看到每個步驟的標題和關鍵字,先確認大方向有沒有問題。
確定了「第五步到第七步之間好像不太對」,再把那個段落展開深入看。
為什麼要這樣設計?
因為上下文是有成本的。當你的 session 累積到幾十萬 token,模型的「注意力」會被稀釋,就像房間裡的背景音樂太大聲,你對著它說話會越來越費力。這種現象叫做「上下文腐蝕」(Context Rot)。一次把全部上下文砸給 AI,它其實處理不了那麼多,效能反而下降。
具體的做法:
用 session observer 工具,先批次抓取所有步驟的前 50 個字,找到有問題的節點(例如某個環節一直重試或某個工具一直噴錯誤),再針對那個節點單獨展開,細看它的完整執行過程和錯誤輸出。
好處是:你可以在短時間內判斷「整個流程哪裡有問題」,不需要等 AI 總結完幾十萬字的 session 才能猜測大概是哪裡出錯。
原則五:定期幫 Skill 做健康檢查

Anthropic 對 Skill 的格式有一套規範,目的是讓 AI 每次載入 Skill 的時候,能夠真正理解裡面的結構:觸發條件是什麼、核心工具在哪裡、使用說明怎麼讀。這就像一本工具箱要有清楚的分層:常用工具放最外層、輔助工具放內層、緊急說明放最上層。
但 AI 在修改 Skill 的時候,有一個很常見的問題:貪方便。
它可能把原來整整齊齊的結構全部打掉,把所有東西塞進一個巨大的 prompt 裡。或是在 /scripts/ 資料夾裡東放一個、西放一個,最後 tool_call 的時候根本抓不到檔案。
這些變化一開始不會被發現,直到某一天 Skill 突然表現異常,你才發現:「咦,這個工具的路徑怎麼跟 SKILL.md 裡寫的不一樣?」
解決方法:建立一個「Skill 維護 agent」,專門負責定期檢查兩件事:
第一,格式是否合規。 確認 SKILL.md 的結構完整、工具指令碼放在正確位置、觸發條件是否寫得夠清楚。Anthropic 的格式建議中,有一點很實用:使用 XML 標籤區分 AI 的思考過程與實際行動,例如用「思考標籤」標示思考、用「工具標籤」標示工具呼叫。
這樣當 AI 載入 Skill 時,能清楚區分「在想什麼」和「在做什麼」,而不是把所有資訊全部混在一起。
第二,描述與行為是否一致。 SKILL.md 說「這個工具輸出的檔案會放在 /output/ 資料夾」,但實際測試時發現它把檔案丟在 /tmp/。這種「說跟做不一樣」的情況,是 Skill 失敗的隱形殺手。
定期健檢,就像每季整理一次房間,把東西安回該放的位置。不然房間會越住越亂,最後東西藏在角落裡,連你自己都找不到。
原則六:測試要用「過/不過」判定,不要用「感覺還不錯」

你把 Skill 修好了,跟自己說:「這次看起來應該可以了。」
放到正式環境用。第一次,完美。第二次,完美。第三次,某個環節突然爆掉。
問題在哪裡?
問題在「看起來可以了」不是一個有效的檢驗標準。
「感覺還不錯」不是標準,「1 到 5 分」也不是標準。
為什麼 1 到 5 分不好?因為每個人對「3 分」的定義都不一樣。同樣是 3 分,有人覺得「及格」有人覺得「有點糟」,十個人可以給出十種不同的解讀,這個指標廢掉了。
有效的檢驗標準長這樣:每一條都是「有就是 1,沒有就是 0」。
以下是幾個可以直接拿出來用的實戰指標:
格式遵循度: 輸出的 JSON 是否能被系統直接解析?結構對不對、欄位名稱對不對?透過就是 1,不透過就是 0。
幻覺攔截: 當使用者詢問資料庫裡沒有的資訊時,Agent 是否精準回答「不知道」而不是瞎掰?這是一個常被忽略但非常重要的指標,因為 AI 瞎掰時通常說得很有自信,看起來比說「不知道」還厲害,但恰恰是「不知道就說不知道」才是一個好的 Skill 該有的能力。
工具呼叫準確率: 是否選擇了正確的工具,並填對了必填引數?透過就是 1,不透過就是 0。
一個有效的裁判:LLM-as-a-Judge。
你可能會想:「這些 0/1 判斷,如果每一次都要我親自看,那我豈不是還是被綁住了?」
答案是:你可以把「裁判」的工作交給另一個 AI。請一個速度快、費用低的小模型,專門跑這些檢驗判斷。例如把你的檢驗標準寫成一個 prompt,叫那個小模型對每一個 Skill 版本跑一次,自動產出「透過了哪些專案、哪些專案失敗」的報告。
這樣你就可以專注在「如何最佳化失敗的專案」,而不是把時間燒在「一個一個手動檢查」這件事上。
一個關鍵的觀念:AI 的隨機性不只影響結果,更影響過程。
很多人以為「AI 犯錯」是運氣不好,但其實問題藏在每一步的隱性決策裡。
AI 執行每一個步驟時,都充滿了隱性決策:這段話該不該濃縮?這裡該用哪個工具?輸出格式要嚴格遵守還是稍微放寬?這些小決定累積下來,會讓同樣的 Skill 在不同時間、不同上下文下,表現出截然不同的結果。
而「機率不是你的敵人,累積才是」這個說法的意思是:
如果每一步的成功率是 90%,執行十步之後,整體成功率是多少?
數學告訴你:0.9 的十次方等於 34.9%。你有超過六成的機率會在某個地方爆掉。
這就是為什麼設定「幾次為一個測試單位」很重要。不要只跑一次就說「成功了」,要跑十次,看有幾次成功。成功率 9/10 和 7/10,代表的是 Skill 成熟度完全不同的兩個階段。
原則七:好版本要立刻存檔

這是最容易被跳過的一步,但也是代價最高的一步。
你花了很長時間,把 Skill 迭代到一個「十次執行九次成功」的高品質版本。你很興奮,繼續最佳化,想把第十次也修好。沒想到下一版改了某個地方,反而把核心功能弄壞了。你已經沒有辦法回到那個「九次成功」的版本。
這個感覺就像打 RPG,打到大魔王前一刻,覆蓋了存檔。
每當你測出一個高成功率的版本,立刻存一版。
就像你打遊戲,進大魔王房間前,一定先手動存一個檔,再挑戰。這個動作看起來很土,但能救命。
心態建設:這是一套系統工程,不是聊天

走到這裡,我想跟你說一個很重要的觀念轉換。
從「寫 Prompt」到「設計 Skill」,本質上是從「跟機器人聊天」轉變為「軟體工程系統設計」。
剛開始用 AI,你只是想要它幫你做一件事,你們之間是「一問一答」的關係。但當你開始設計 Skill,你其實在做一件事:把一個人的工作流程翻譯成 AI 能執行的系統。你要定義觸發條件、工具鏈路、錯誤處理、版本管理。這不是聊天,這是系統設計。
前期一定痛苦。
你會覺得:「我只是想要它自動整理筆記,為什麼要先花兩天建立測試標準?」
答案是:因為沒有測試標準,你就不知道什麼時候「整理好了」。沒有目標定義,你就會一直陷在來回修改的輪迴裡。沒有版本管理,你的好版本就會被覆蓋掉。
但這個前期痛苦是值得的。
當你的 Skill 設計好了,它可以像一個自動化員工一樣,24 小時執行你定義的工作流程,不再需要你每次都重新解釋你要什麼。這是讓 AI 從「玩具」變成「真正的工具」的必經之路。
阿魁碎碎念
說一個很真實的:你迭代 Skill 的時候,錢真的會在你不注意的地方燒掉。Agent 自己迭代的時候,目標如果沒定義清楚,它會在錯誤的方向上走很久,但它不會喊累,也不會說「老闆這樣下去不行」。它只會一直燒 token。
所以我的建議是:每迭代三次,強制暫停一次,回頭確認方向。 這個暫停看起來浪費時間,但實際上是在省最多的時間和金錢。
第一步先把「目標」討論清楚,後面每一個步驟都會省很多力氣。這是看起來最笨、但其實最聰明的做法。