
為各種任務打造的通用調度幫手:Claude Code 的動態工作流程
Claude Code 的動態 workflows,讓 AI 能為不同任務即時生成執行框架,把長任務、平行驗證與審查拆成可治理的流程。


本篇內容由倉鼠特報員 AI 協助產出。
倉鼠碎碎念:
這篇其實是在講 Claude Code 走向『自己替任務寫作業流程』的關鍵一步。好處很明顯:長任務、平行驗證、反覆審查不再全塞進同一個 context 裡硬撐;但代價也很現實,tokens 會燒、流程會變複雜。最值得看的不是新功能多炫,而是它把 agent 失敗模式拆成可治理的工程問題。
解讀來源:
翻譯自:https://x.com/trq212/status/2061907337154367865
https://claude.com/blog/a-harness-for-every-task-dynamic-workflows-in-claude-code
正文開始
上週,我們在 Claude Code 發布了動態工作流程(dynamic workflows)。現在 Claude 可以即時替自己寫出一套 代理式執行框架(harness),也就是依照當下任務客製打造的一組步驟、角色與檢查規則。
Claude Code 預設的代理式執行框架(harness)是為寫程式而設計,但它也適合很多其他型別的任務。原因很簡單,很多工作其實都長得很像寫程式任務。不過,有些任務型別若想達到最佳表現,我們過去必須在 Claude Code 之上另外打造客製執行框架,例如研究、資安分析、代理團隊(Agent teams),或程式碼審查。
工作流程(workflows)讓你可以動態建立執行框架(harness),讓 Claude 在 Claude Code 裡原生處理上述所有問題,甚至更多問題。你也可以把這些 workflows 分享給別人並重複使用。
這篇文章會整理我初步使用 workflows 的經驗與學到的東西,幫助你更好地使用它。
不過要先說,最佳實踐還在發展中!動態 workflows 通常會消耗更多 tokens,所以要仔細思考什麼時候該用,以及該怎麼用。這裡的 tokens 可以先理解成模型運算與閱讀上下文的成本。
註:這篇文章也發布在 Claude Blog。
範例提示詞(prompts)
進入技術細節之前,我想先用幾個範例提示詞(prompts),幫你想像 workflows 可以做到什麼:
「這個測試大概 50 次會失敗 1 次。請建立一個 workflow 來重現它、提出假說,並在工作樹(worktrees)裡用對抗方式測試這些假說。/goal 在有一個假說成立以前不要停止。」
「用一個 workflow 檢查我最近 50 次 session,挖出我一直在修正你的地方,然後把反覆出現的修正整理成 CLAUDE.md 規則。」
「用一個 workflow 搜尋過去六個月 Slack 的 #incidents,找出反覆出現、但還沒有人開 ticket 的根因。」
「拿我的商業計畫跑一個 workflow,讓不同代理(agents)分別從投資人、客戶、競爭對手的角度把它拆解批判。」
「這裡有一個包含 80 份履歷的資料夾,請用 workflow 替後端職缺排序這些履歷,並重新檢查前十名。請用 AskUserQuestion 工具訪談我,建立評分規準。」
「我需要替這個 CLI 工具取名字。用一個 workflow 發想一堆選項,然後跑一場錦標賽式評比(tournament)選出前三名。」
「用一個 workflow 把我們的 User model 在所有地方重新命名為 Account。」
「檢查我的部落格草稿,用一個 workflow 對照 codebase 驗證每個技術主張,我不想發布任何錯誤內容。」
動態 workflows 如何運作
動態 workflows 會執行一個 JavaScript 檔案,裡面有幾個特殊函式,用來生成與協調子代理(subagents)。

動態 workflows 也包含標準 JavaScript 函式,例如 JSON、Math、Array,方便處理資料。
特別值得知道的是,動態 workflows 可以決定某個代理(agent)使用哪個模型,也可以決定子代理(subagents)是否要在各自的工作樹(worktree)裡執行。這讓 Claude 可以依任務需要選擇適當的智慧層級與隔離程度。
如果 workflow 被中斷,例如使用者操作或關閉終端機,恢復工作階段(session)後,workflow 可以從中斷處繼續。
為什麼需要動態 workflows
當你要求預設的 Claude Code harness 完成一個任務時,它必須在同一個上下文視窗(context window)裡同時規劃與執行。對很多寫程式任務來說,這非常有效。但遇到長時間執行、大量平行處理,或高度結構化且帶有對抗性的任務時,它有時會失效。
原因是 Claude 在單一上下文視窗(context window)裡處理複雜任務越久,就越容易出現幾種特定失敗模式:
Agentic laziness 指的是 Claude 在面對特別複雜、多步驟任務時,還沒真正完成就停下來,並在只取得部分進展後宣稱任務已完成。例如安全審查有 50 個專案,它只處理了其中 20 個。
Self-preferential bias 指的是 Claude 傾向偏好自己的結果或發現,尤其是當你要求它依照評分規準驗證或評判自己輸出的內容時。
Goal drift 指的是在多輪互動中,Claude 對原始目標的忠實度會逐漸下降,尤其是在 compaction 之後。每一次摘要都會造成資訊損失,像是邊界條件需求或「不要做 X」這類限制,很容易在過程中遺失。
建立 workflow 可以協調多個彼此分離的 Claude,讓它們各自擁有自己的上下文視窗(context window)與隔離目標,進而對抗這些問題。
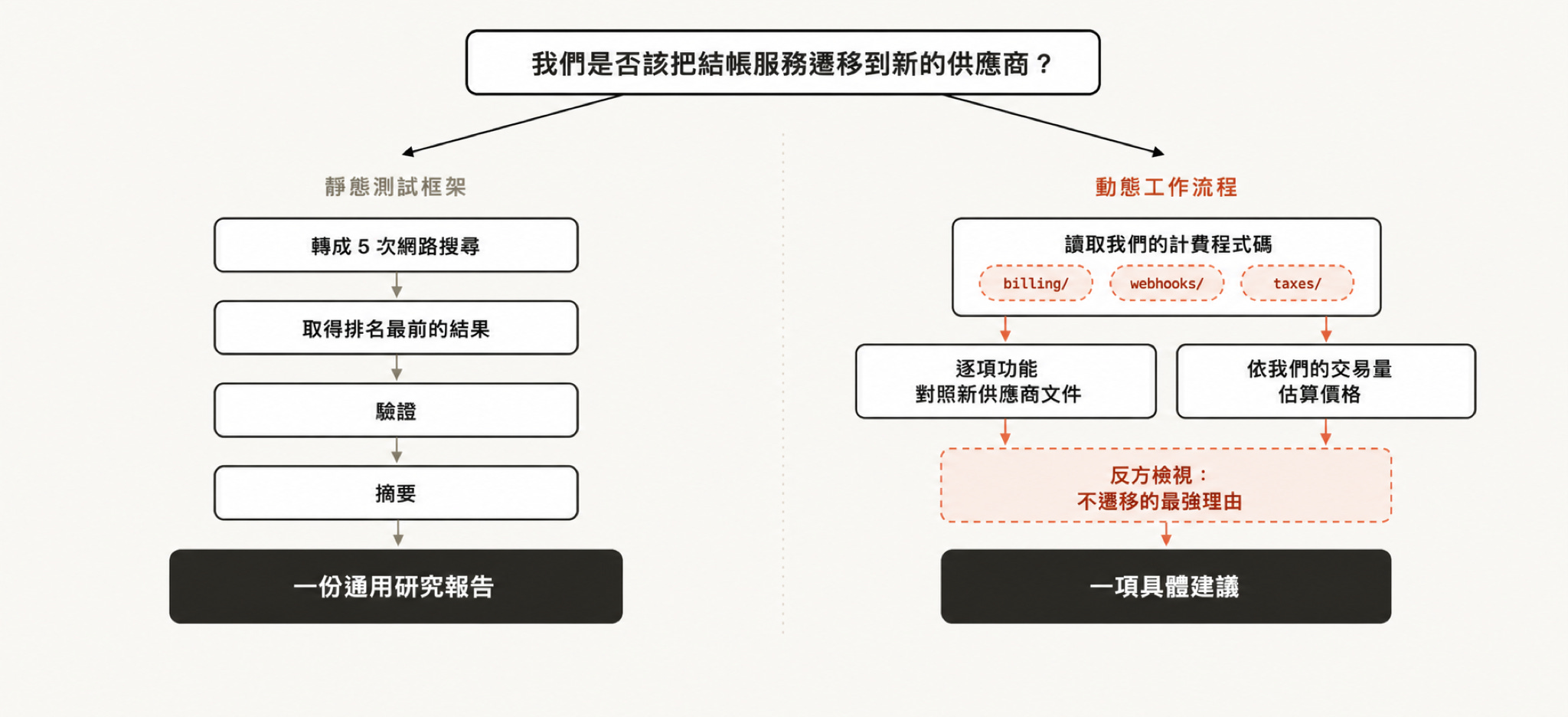
動態 workflows vs 靜態 workflows
你可能以前已經用 Claude Agent SDK 或 claude -p 建立過靜態工作流程(static workflow),用來協調多個 Claude Code 例項一起工作。
但因為靜態 workflows 必須事先涵蓋所有邊界情況,所以通常更通用、也更笨重。隨著 Claude Opus 4.8 與動態 workflows 出現,Claude 現在已經聰明到可以為你的使用情境量身打造客製執行框架(harness)。
使用動態工作流程(workflows)時的實用模式
你可以直接要求 Claude 建立一個 workflow,或使用觸發詞「ultracode」,確保 Claude Code 會建立 workflow。
不過,如果你能建立一個關於動態 workflows 如何運作的心智模型,就會更容易判斷什麼時候該用,也更知道可以怎麼用提示詞(prompt)引導 Claude。
Claude 在建立 workflows 時,常會使用並組合幾種常見模式:
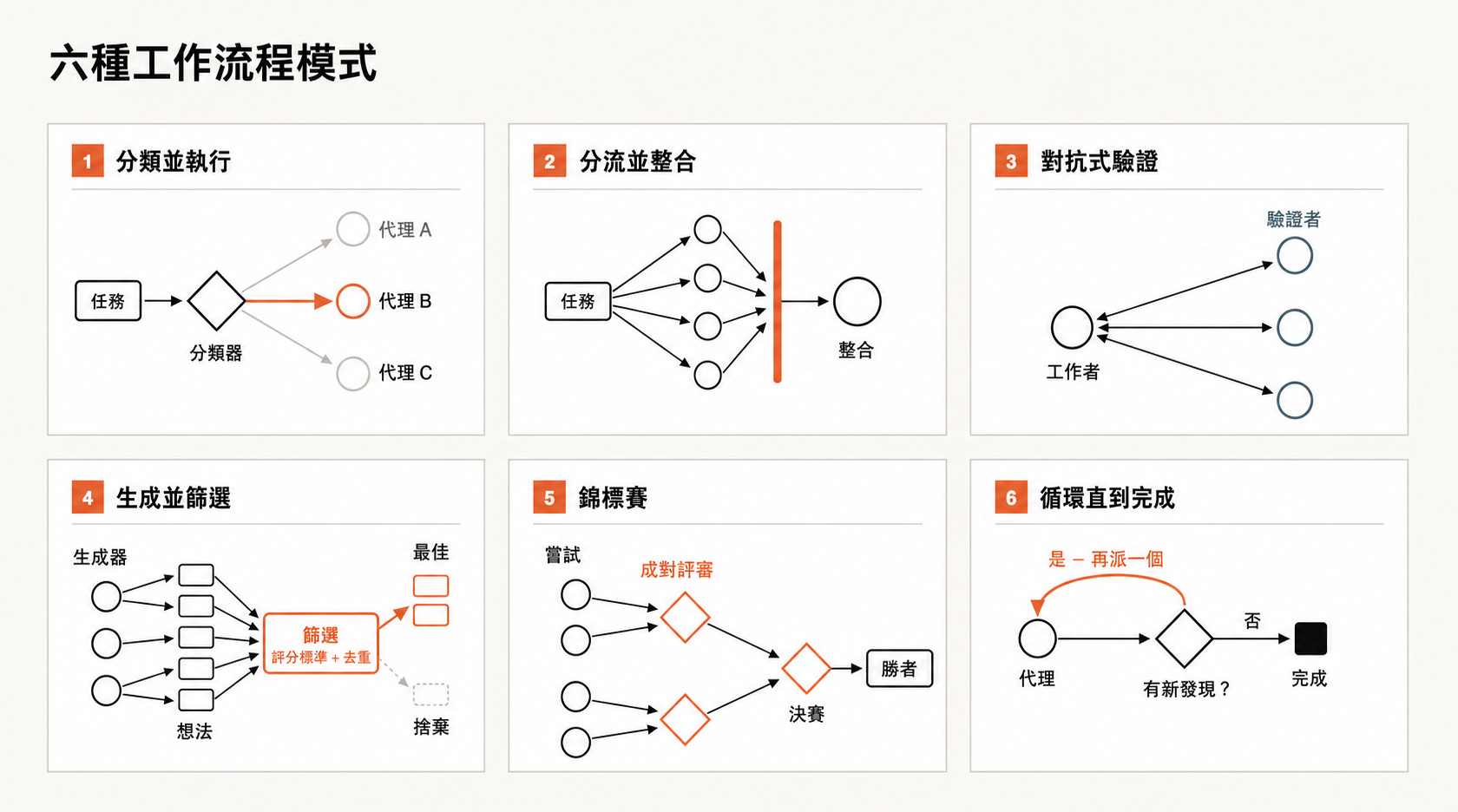
分類後行動(Classify-and-act)
使用一個分類器代理(classifier agent)判斷任務型別,然後依照任務型別路由到不同 agents 或不同處理方式。也可以在流程最後使用分類器判斷輸出。
扇出再彙整(Fan-out-and-synthesize)
把任務拆成許多較小步驟,讓一個 agent 處理一個步驟,最後再彙整結果。當步驟數量很多,或每個步驟都需要乾淨、獨立的上下文視窗(context window),以免彼此干擾時,這特別有用。彙整步驟像一道同步關卡(barrier),會等待所有扇出去的 agents(fan-out agents)完成,再把它們的結構化輸出合併成單一結果。
對抗式驗證(Adversarial verification)
對每個生成出來的 agent,再生成另一個 agent,依照評分規準或條件,用對抗方式驗證它的輸出。也就是不要讓同一個代理自己替自己打分數。
生成後篩選(Generate-and-filter)
針對某個主題生成大量想法,然後依照評分規準或驗證流程過濾、去重,只保留品質最高且經過測試的想法。
錦標賽式評比(Tournament)
這不是把工作拆開,而是讓 agents 彼此競爭。做法是生成 N 個 agents,讓它們用不同方法嘗試同一個任務,然後由提示詞(prompt)或模型透過裁判代理(judge agent)兩兩比較結果,像錦標賽一樣一路淘汰,直到選出勝者。
持續迴圈直到完成(Loop until done)
對於工作量未知的任務,持續迴圈(loop)並生成 agents,直到滿足停止條件,例如沒有新發現,或記錄檔(logs)裡不再有錯誤,而不是固定執行幾輪。
使用情境
你可以更有創意地思考什麼時候、如何要求 Claude Code 建立動態 workflows。我發現 workflows 有時在非技術工作上甚至更有用。

遷移與重構
Bun 是用 workflows 從 Zig 重寫成 Rust 的。你可以閱讀 Jarred 的 X 推文串瞭解更多細節。
關鍵是把任務拆成一連串需要處理的步驟,例如呼叫點(callsites)、失敗測試、模組(modules)等。針對每個待修單位,在工作樹(worktree)裡派出一個子代理(subagent)進行修復,接著再由另一個 agent 進行對抗式審查,最後合併。
你也可以考慮要求 agent 不要使用資源密集型指令,這樣才能最大化平行處理,又不會耗盡本機資源。
深度研究
我們在 Claude Code 裡發布了一個使用動態 workflows 的深度研究 skill(/deep-research)。具體來說,它會把網頁搜尋扇出去平行處理(fan-out),抓取來源、用對抗方式驗證來源主張,最後彙整成一份附引用的報告。
但你可以把這類研究用在不只是網頁搜尋的場景。例如,要求 Claude 從 Slack 上下文(context)彙整狀態報告,或透過深入探索程式碼庫(codebase),研究某個功能是如何運作的。
深度驗證
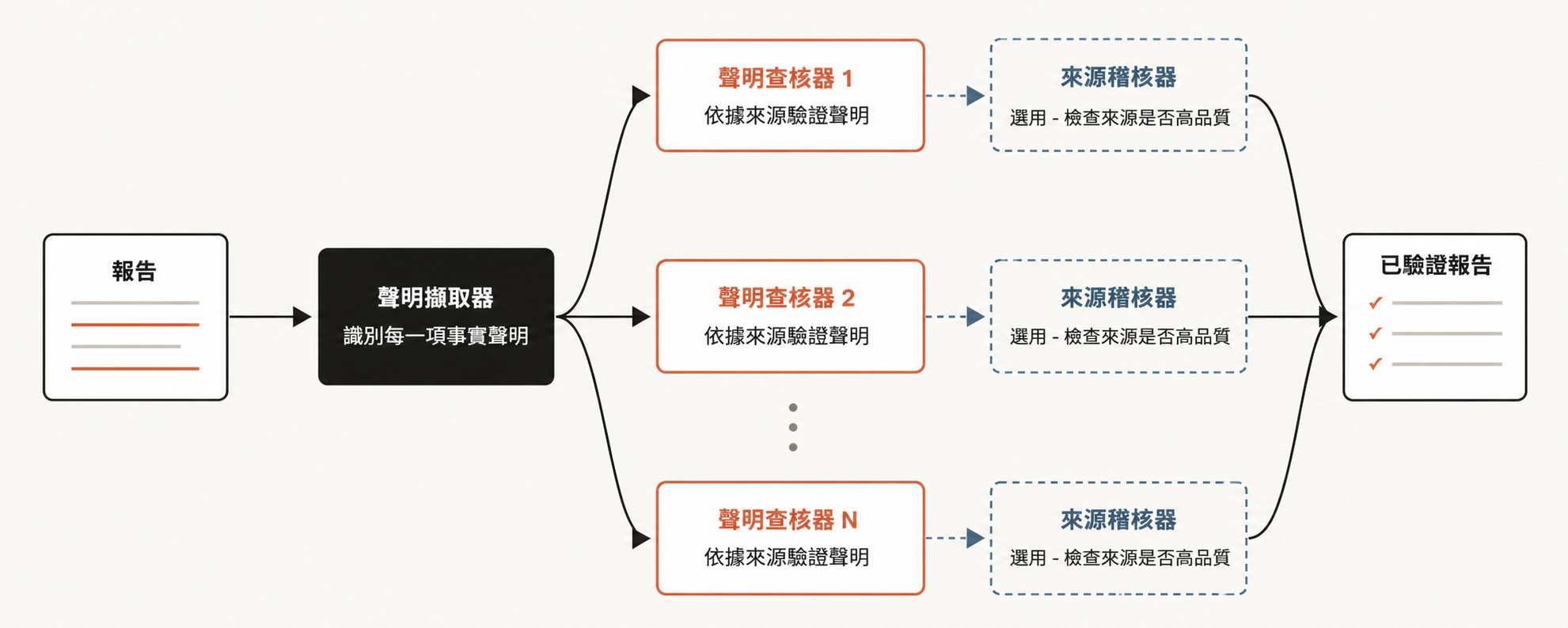
另一方面,如果你有一份報告,希望檢查並替它引用的每個事實主張找到來源,那你可能會想生成一個 workflow,先讓一個 agent 找出所有事實主張,再針對每個主張派出一個 subagent 進行細部查核。你也可以再派一個驗證 agent 檢查來源 subagent,確認它找到的來源品質足夠高。
排序
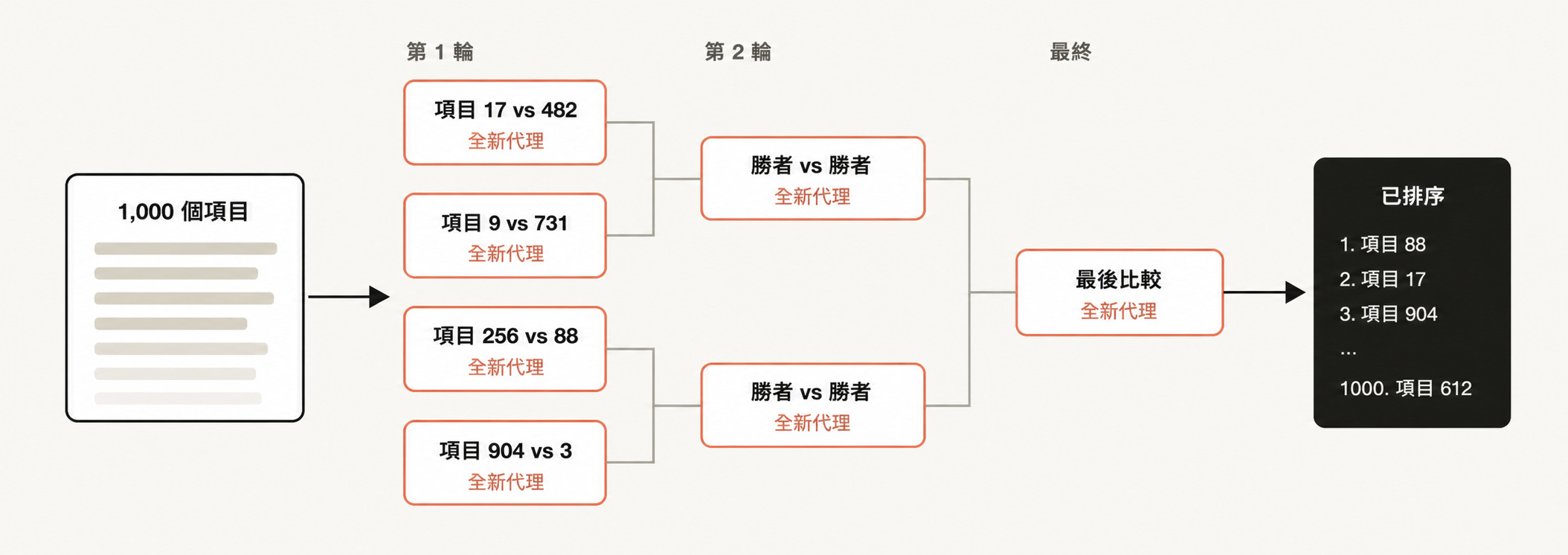
你可能有一份專案清單,想根據某種 Claude Code 擅長評估的質性標準進行排序。例如,把支援 tickets 依照 bug 嚴重程度排序。但如果你試著在單一提示詞(prompt)裡排序 1000 筆以上資料,品質會下降,而且上下文(context)也裝不下。
更好的做法,是把排序改成一場錦標賽式評比(tournament),或建立一條由兩兩比較代理組成的流程(pairwise-comparison agents pipeline)。也可以先把資料平行分桶排序(bucket-rank),再合併結果。
成對比較通常比直接給絕對分數更可靠。每次比較都交給一個獨立 agent,固定規則的迴圈(deterministic loop)只負責維持淘汰賽對戰表(bracket)與目前排序,context 裡不用一次塞進全部資料。
記憶與規則遵守
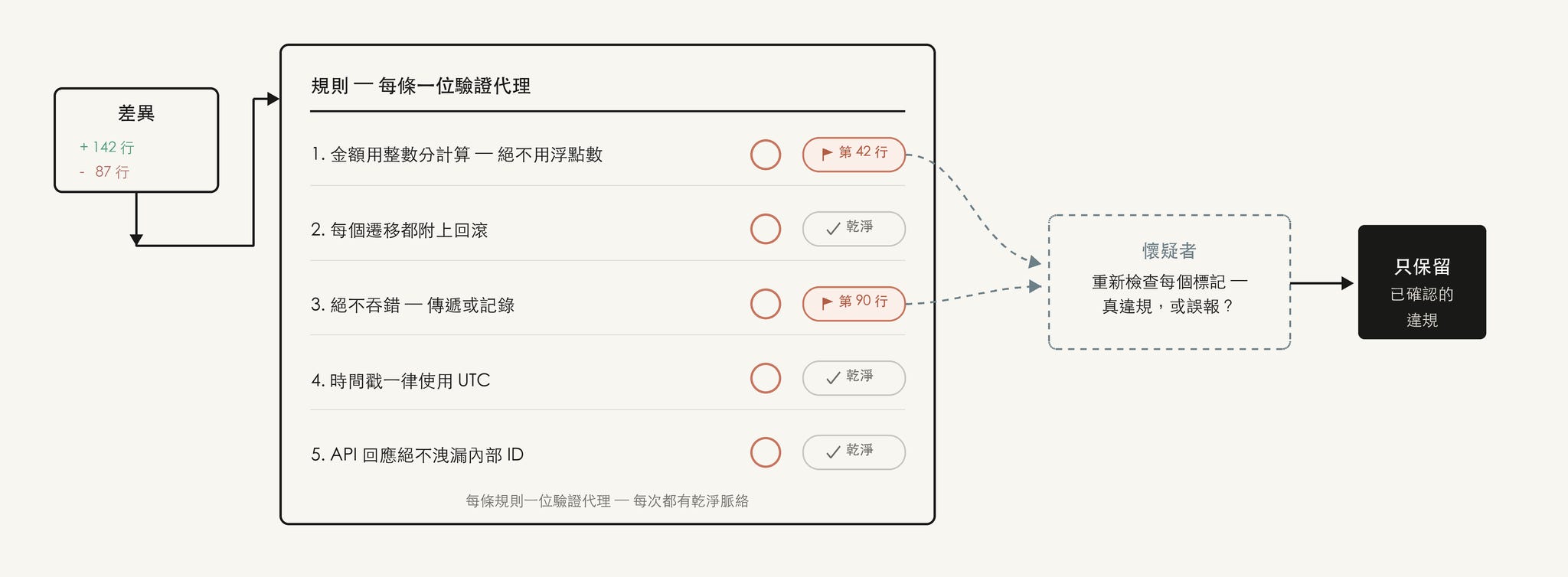
如果你有一組特定規則,發現 Claude 即使寫進 CLAUDE.md 仍然常漏掉或做不好,可以建立一個 workflow,把必須檢查的規則列出來,並讓驗證代理(verifier agents)逐條檢查,一條規則一個 verifier。建立一個懷疑者人格的子代理(skeptic persona subagent)來審查這些規則是否合理,也能幫助避免太多誤報。
反方向也可行:挖掘你最近的工作階段(sessions)與程式碼審查留言(code review comments),找出你一直在做的修正,讓平行 agents 將它們分群,對每個候選規則進行對抗式驗證,確認這條規則是否真的能防止過去發生過的錯誤,最後把驗證後留下來的規則萃取回 CLAUDE.md。
根因調查
除錯(debugging)最有效的方式,是先提出幾個彼此獨立的假說並加以測試。但如果你只使用單一上下文視窗(context window),Claude 可能會陷入自我偏好(self-preferential bias),也就是更容易相信自己前面提出的答案。
Workflow 可以透過結構化方式防止這點,例如生成多個 agents,讓它們根據互不重疊的證據提出假說。你可以分別派 agents 檢查記錄檔(logs)、檔案(files)與資料(data)。接著,每個假說都要面對一組驗證者(verifiers)與反駁者(refuters)。
這不只適用於寫程式。Workflows 也可以用在銷售,例如為什麼三月銷售下滑;資料工程,例如為什麼這條資料流程(pipeline)失敗;或任何事後檢討練習。
大規模分流處理
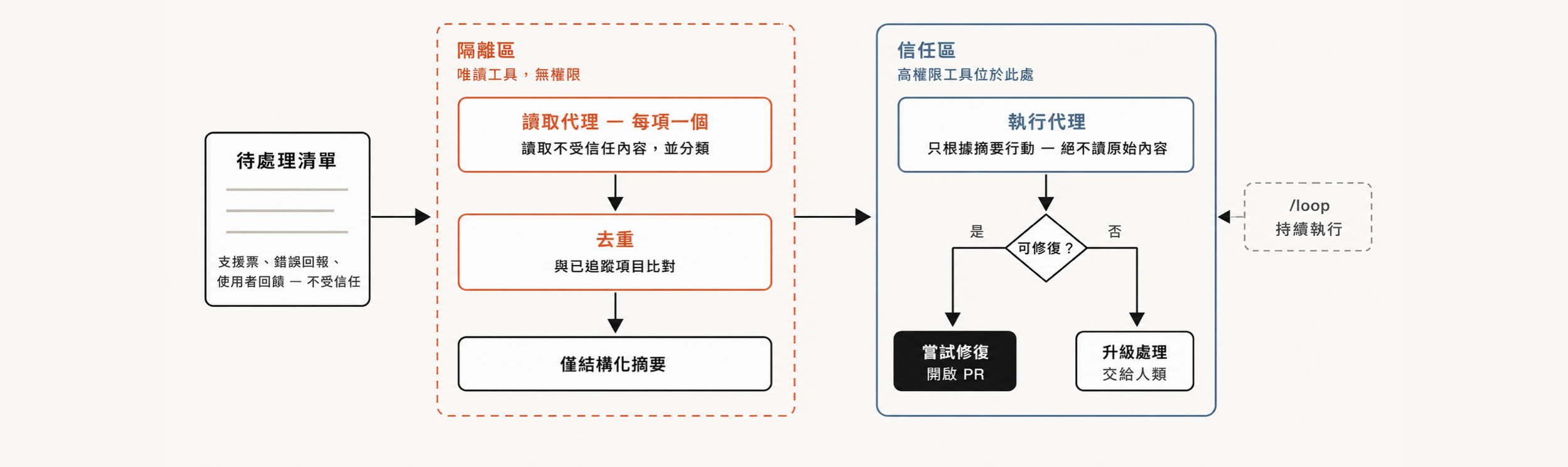
每個團隊都有支援佇列(support queue)、bug reports,或某種無法完全由人類處理的待辦積壓(backlog)。
分流處理工作流程(triage workflow)可以分類每一筆待處理內容、對照既有追蹤紀錄去重,然後採取行動。這可能是嘗試修復,也可能是升級交給人類使用者。
Triage workflows 裡一個很有用的模式是隔離區(quarantine)。意思是,禁止那些讀取不受信任公開內容的 agents 執行高風險操作,真正的行動由負責處理資訊的 agents 執行。
把 triage workflows 搭配 /loop,就可以讓 Claude 持續執行。
探索與品味
當你在探索不同解法時,workflows 也很有用,尤其是像設計或命名這種偏品味判斷、又會受益於評分規準的任務。
你可以要求 Claude 探索一批解法,並提供審查代理(review agent)一套「好解法應該長什麼樣」的評分規準。當 review agent 覺得已經符合條件時,任務就完成。解法也可以根據評分規準透過錦標賽式評比(tournament)排序或選出。
Evals
你可以針對特定任務跑輕量評測(evals)。做法是在工作樹(worktree)裡派出多個獨立 agents,再派出比較代理(comparison agents)依照評分規準比較並評分具體輸出。例如,針對你建立的某個 skill,以特定評分條件(criteria)評估並反覆改進它。
模型與智慧路由
建立一個針對你任務調校過的分類器代理(classifier agent),讓它決定要使用哪個模型。當任務會涉及大量工具呼叫,且執行前的研究能幫助判斷最適合的模型時,這會很有幫助。
舉例來說,「解釋 auth module 如何運作」這個任務,最適合的模型取決於 auth module 裡有多少檔案,以及程式碼庫(codebase)的形狀。分類器代理(classifier agent)可以先做這項研究,再根據預期複雜度路由到 Sonnet 或 Opus。
什麼時候不該使用動態 workflows
Workflows 還很新。雖然在很多情境下它能創造超額成果,但不是每個任務都需要它,而且它可能會消耗顯著更多 tokens。
最好是有創意地使用 workflows,把 Claude Code 推向你以前沒嘗試過的方向。對一般寫程式任務來說,先問自己:這真的需要更多運算量(compute)嗎?例如,多數傳統寫程式任務不需要一個由 5 位審查者(reviewers)組成的評審團。
建立動態 workflows 的 tips
Prompting
針對動態 workflows,使用詳細的提示方式(prompting),並套用上面描述的具體技巧,通常會得到最好的結果。
Workflows 不只適合大型任務。你也可以提示(prompt)模型使用「快速工作流程(quick workflow)」。例如,建立一個快速的對抗式審查,檢查某個假設是否成立。
搭配 /goal 與 /loop
使用可重複執行的 workflows 時,例如分流處理(triage)、研究(research)或驗證(verification),可以搭配 /loop 定期執行,並用 /goal 設定硬性完成條件。
Token 使用預算
你可以替動態 workflows 設定明確的 token 使用預算,限制某個任務可以消耗多少 tokens。你可以在 prompt 裡寫「use 10k tokens」,這會設定上限。
儲存與分享動態 workflows
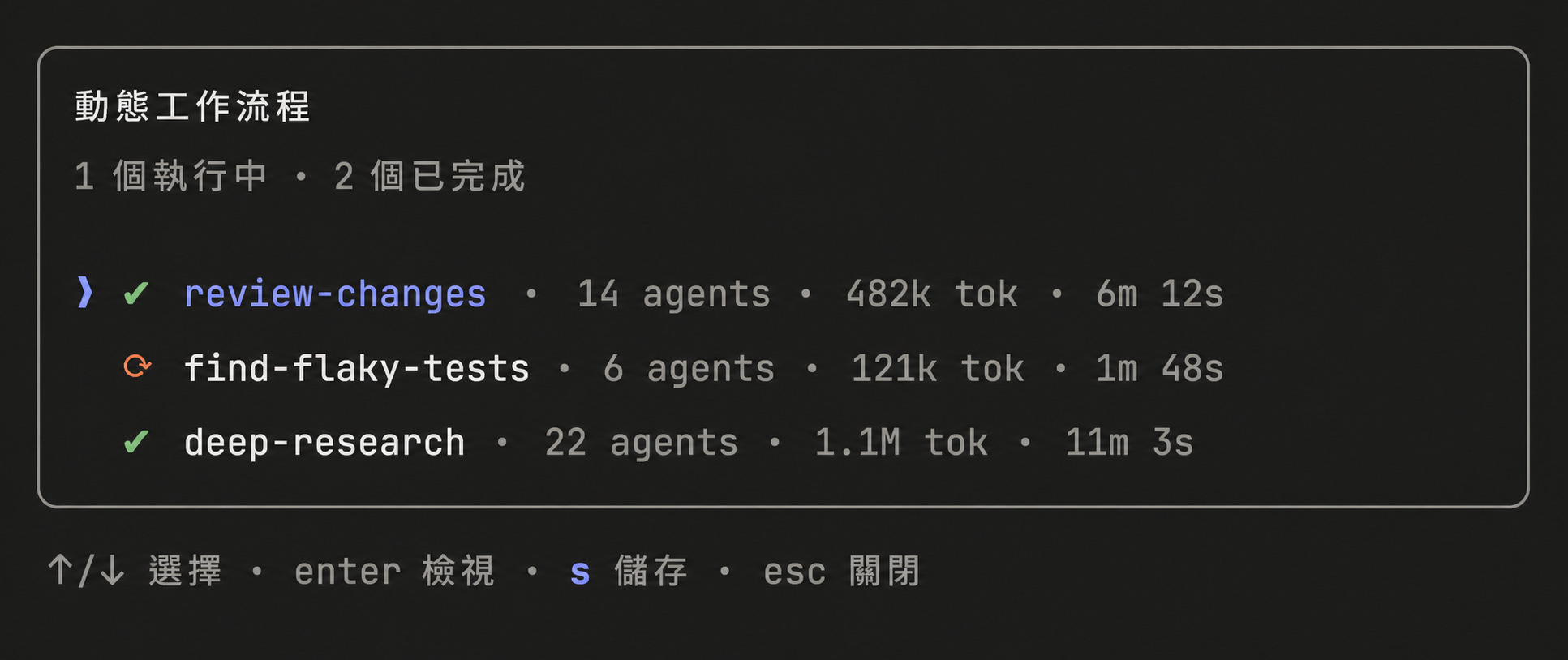
你可以在 workflow menu 裡按「s」來儲存 workflows。你可以把它們提交到(check into)~/.claude/workflows,或透過 skill 分發。
若要透過 skill 分享,請把 JavaScript workflow files 放進 skill 資料夾,並在 SKILL.MD 裡引用它們。為了保留更多彈性,你可以提示 Claude 把 skill 裡的 workflows 視為範本(template),而不是必須逐字執行的程式碼(script)。

一個全新的世界
Workflows 是延伸 Claude Code 能力的一種有用新方式。我鼓勵你把它視為起點,關於如何最好地使用它,還有很多東西值得探索。歡迎告訴我們你發現了什麼。
Thariq Shihipar 與 Sid Bidasaria(@sidbid)是 Anthropic 的 technical staff,負責 Claude Code。