
關於 Google 演算法洩漏的脈絡,及洩漏算法中獲得的洞察(漲知識!)
Google 的演算法竟然洩漏了,就讓我們來一窺其中的秘密吧!


前言
2024 年 5 月 5 日,一位 SEO 專家 Erfan Azimi 向 Rand Fishkin 提供了一份 Google 演算法洩漏文件。
這份洩漏文件第一時間被交給了 Rand Fishkin,雖然他已經離開 SEO 多年,但曾經的影響力,讓 Erfan Azimi 決定第一時間交給他並由他優先發佈,看看 Rand Fishkin 的經歷及影響力就知道為什麼:
2001 年開始為西雅圖地區的小型企業進行 SEO,並於 2003 年共同創立了後來成為 Moz(原名 SEOmoz)的 SEO 諮詢公司。
在接下來的 15 年裡,在搜尋行銷行業工作,並經常被認為是該領域的有影響力的領導者。撰寫/合著了《Lost and Founder: A Painfully Honest Field Guide to the Startup World》、《The Art of SEO》和《Inbound Marketing and SEO》。
包括《華爾街日報》、《Inc.》、《福布斯》在內的多家出版物以及數百家其他媒體,都曾撰文並引用 Rand 對 SEO 和 Google 搜尋領域的見解,許多媒體還引用了 Rand 主持了十年的熱門每週影片系列《白板星期五》。
Moz 成長到擁有超過 35,000 名付費客戶的 SEO 軟體公司,收入超過 5000 萬美元,並擁有約 200 人的團隊,於 2021 年被出售給私募股權買家。Rand 在 2018 年離開並創立了 SparkToro,並於 2023 年創立了 Snackbar Studio。
Rand 於 2001 年從華盛頓大學輟學,沒有學位,但 Rand 的 Google 和 SEO 工作已被美國國會、美國聯邦貿易委員會、《華爾街日報》、《紐約時報》和約翰·奧利弗的《上週今夜》等數十個機構引用。
Rand 擁有多項有關網路規模連結索引設計的專利,並且是多種連結索引指標的建立者,包括域名權威度,一種基於機器學習的分數,通常用於數位行銷領域來評估網站在Google搜尋引擎中的排名能力。
不知道怎麼選 SEO 課程嗎?可以參考 Frank 的 SEO 課程推薦:2025 年國內外 13 堂 SEO 課程推薦!
這份文件是否可信?
根據兩名匿名前 Google 員工表示:
我在那裡工作時沒有接觸到這段程式碼,但這看起來確實是真的。
它具備所有內部 Google API 的特點。
這是一個基於 Java 的 API,有人花了很多時間遵循 Google 的內部標準來編寫文件和命名。
我需要更多時間才能確定,但這與我熟悉的內部檔案一致。
有興趣但怕內容太長的話,也可以看看逗比叔叔在科技人寫的『小型網站在當今 SEO 生態下的生存之道』!
Google API 內容倉庫是什麼?
洩漏文件來自 GitHub。此洩漏與公開 GitHub Repo 和 Google 的 Cloud API 檔案中的其他洩漏相符,使用相同的符號風格、格式,甚至過程/模組/功能名稱和參考。
根據前 Google 員工的消息,幾乎每個 Google 團隊都有這樣的檔案,解釋各種 API 屬性和模組,以幫助項目成員熟悉可用的資料元素。
Google 搜尋則是世界上最秘密、最嚴密保護的黑箱之一。在過去的二十幾年,從未有過來自 Google 搜尋部門如此規模或詳細的洩漏報告。
文件中提到的排名特徵多達 14,000 個,而且還不止這些,其中大約有 8,000 個與搜尋有關。
在 API 檔案中有 2,596 個模組,包含 14,014 個屬性(功能),看起來像這樣:

這些模組涉及到 YouTube、Assistant(助理)、Books(圖書)、影片搜尋、連結、網頁檔案、爬蟲基礎設施、內部日曆系統以及 People API 等多種組件。
洩露的文件詳細說明了 API 的每個模組,並將其分解為摘要、類型、函數和屬性。主要內容是各種屬性定義,這些定義會在排名系統中被調用,以生成搜尋引擎結果頁面(SERPs),即 Google 在使用者進行查詢後顯示給他們的結果。
閱讀洩漏文件的注意事項
我們怎麼知道 Google 的搜索引擎是否真的使用了這些 API 文件中提到的所有功能?
這個問題可以有不同的解讀。Google 也許已經停用了其中一些功能,把其他功能僅用於測試或內部項目,甚至可能提供一些從未被實際應用過的 API 功能。
然而,在文件中有提及一些已經過時的功能以及特別註明不應再使用的部分。這強烈暗示那些未被如此標記的功能,可能在 2024 年 3 月資料外洩時依然處於活躍狀態。
我們目前還不能確定三月洩露的內容是否為該文件的最新版本。根據我在 API 文件中查到的信息,最新更新日期是 2023 年 8 月。

不要指著這次洩漏中的某個 API 功能就說:「看!這就是 Google 在排名中使用 XYZ 的證據。」這還不能算是證據。這是一個強烈的跡象,比專利申請或Google員工的公開聲明更有力,但仍然不能保證。

文件沒有評分功能資訊。我們不知道在各種下游評分功能中,特徵是如何加權的。
從這些資訊中得出結論時要小心,任何的解釋都有可能是錯誤的。
如果要閱讀洩漏文件,該如何閱讀?(一般讀者可跳過)
從 root 開始:這裡列出了所有模組及其一些描述。在某些情況下,模組中的屬性會被顯示。
請確認你查看的是正確的版本:v0.5.0 是已經修復過問題的版本。我們之前討論的是更早期的一些文檔。

繼續往下滑,直到發現一個讓你覺得有意思的模組:我主要關注搜尋功能,但你也許會對 Assistant 或 YouTube 等其他內容感興趣。
仔細查看屬性:在瀏覽各個功能描述時,留心觀察那些被引用的其他相關功能。
搜尋:在文件中查找這些關鍵字。
不斷重複這個過程直到完成:返回第一步。隨著學習的深入,你會發現更多值得搜尋的內容,也會注意到某些字串可能代表了其他讓你感興趣的模組。
HexDocs 讓人困擾的一點是,左側邊欄遮住了大部分模組的名稱,這樣你就不容易看清楚自己要導覽到哪裡。
如果不想修改 CSS,有個簡單的 Chrome 擴充功能,可以安裝來讓側邊欄變大。



Rand Fishkin 整理的 5 大衝擊波
#1: NavBoost 和如何利用點擊、CTR、長短時停留及用戶資料

在某些文件模塊中提到一些功能,例如“好點擊”(goodClicks)、“壞點擊”(badClicks)、“最後最長點擊”(lastLongestClicks)、展示次數(impressions)、已壓縮(squashed)和未壓縮(unsquashed)的,以及獨角獸點擊(unicorn clicks)。
Google 有辦法過濾掉他們不希望在排名系統中計入的點擊,同時保留那些他們希望計入的,並衡量點擊的持續時間(例如 pogo-sticking:當使用者點選某個結果後,很快又按下返回鍵表示對該答案不滿意)以及曝光次數。
如果 Chrome 點選流資料用於排名,這是否意味著付費點選可以提升自然排名?多年來,很多人注意到這種效果,他們進行大規模的 PPC 購買,然後看到 SEO 大幅提升。
但 Google 同樣能夠控制這一點,透過建立機器學習模型來過濾它。
#2: 利用 Chrome 瀏覽器的點擊行為數據提升 Google 搜尋功能

根據 API 文件,Google 會計算多種不同類型的數據指標,這些指標可以通過 Chrome 瀏覽器查看,不僅適用於單一網頁,也適用於整個網站域名。
它展示了一個名為
topUrl的調用,其內容是一份 “擁有最高two_level_score(即chrome_trans_clicks)的頂級網址列表。”
Google 可能會根據在 Chrome 瀏覽器中的頁面點擊次數,來判斷哪些網址最受歡迎或最重要,並將其納入到 Sitelinks 功能的計算中。

#3:旅行、疫情和政治中的白名單
如果有一個專門介紹 “優質旅遊網站” 的模組,理性的讀者應該可以推斷,在旅遊領域中,Google 有一份白名單(尚不清楚這是否僅適用於 Google 的 “旅行” 搜尋標籤,或是涵蓋更廣泛的網頁搜尋)。
多次提到
isCovidLocalAuthority和isElectionAuthority這些標籤,暗示 Google 會把某些特定的網站列入白名單,以便在面對高度爭議或可能有問題的搜尋時優先顯示出來。例如,在2020年美國總統選舉結束後,有一位候選人宣稱(無任何證據)選舉結果遭到篡改,並煽動他的支持者攻佔國會大廈,對議員們進行可能的暴力襲擊,也就是說發起了一場叛亂。
Google 幾乎肯定會成為人們查詢此事件資訊的第一個地方。如果他們的搜尋引擎顯示的是錯誤描述選舉證據的宣傳網站,那麼這可能會直接引發更多爭議、暴力,甚至威脅到美國民主制度。
#4:採用品質評估員反饋
Google 一直以來都有一個叫做 EWOK 的品質評估平台(SEO 領域知名人物 Cyrus Shepard 曾經多年參與其中,並撰寫了相關文章)。目前發現,有些品質評分員提供的要素被應用到搜尋系統中。
令人驚訝的是,EWOK 品質評估員所產生的分數和數據可能直接影響了 Google 的搜尋系統,而不僅僅是作為實驗用的訓練資料。當然有可能這些資料 “只是用來測試”,但是在查看洩露文件時,如果真是如此,筆記和模塊細節裡應該都會明確的標示出來。
文中提到“人類評分(如來自 EWOK 的評分)”,並指出這些評分 “通常僅在評估流程中使用”。這意味著,它們可能主要作為該模塊的訓練數據。即便如此,這依然扮演著極其重要的角色,市場行銷人員不應輕視品質檢查員對其網站的觀感和打分。
#5: Google 使用點擊數據來確定如何在排名中加權連結
Google 有三個分類等級來分類他們的連結索引(低、中、高品質)。
我們使用點擊數據來決定一個文件應該歸類到哪一級別的連結、圖片索引中。可以在這裡查看
SourceType和TotalClicks的詳細信息。簡而言之:如果 Forbes.com/Cats/ 沒有任何點擊,它會被歸入低品質索引,並且其連結也會被忽略。
如果 Forbes.com/Dogs/ 從可驗證的設備(包括所有之前提到的與 Chrome 有關的數據)獲得大量點擊,那麼它將被歸入高品質索引,其連結也會傳遞排名信號。
當一個連結因為在更高等級的索引中而變得 “可信” 時,它能夠傳遞 PageRank 和錨點,反之則可能會被連結垃圾系統過濾或降權。
但來自低品質連結與索引的連結不會影響網站排名,這些連結只會被忽視。
這是 Google 的謊言,亦或另有隱情
文件中的一些線索,揭露出平常跟 Google 公開消息不符合的面向,部分會與剛剛的五大衝擊有重疊到。
“We Don’t Have Anything Like Domain Authority”

他們說不使用 Domain Authority,可能是指他們特別不使用 Moz 的指標 DA(很明顯 🙄)。Google 還表示,他們並不評估某個網站在特定主題(或領域)上的權威性或重要程度。
由於語義上的混淆,他們可以避免直接回答是否計算或使用整個網站的權威性指標這個問題。

事實上,在 Google 的系統中,每份文件都會存儲一些壓縮後的品質信號,其中就有一項名為 “siteAuthority” 的指標。

目前還不清楚這項指標具體是怎麼計算的,也不知道它在後續的評分功能中是如何應用的,但可以肯定的是它確實存在並且被用於 Q* 排名系統。這項線索明確顯示,Google 的確擁有一個總體域名權重。
Mike:這時候,Google 的員工可能會說:『我們確實有這個技術,但並沒有用上。』 或者『你根本不了解那是什麼意思。』
“We Don’t Use Clicks for Rankings”

在最近的美國司法部(DOJ)反壟斷審判中,Pandu Nayak 的證詞揭露了 Glue 和 NavBoost 排名系統。NavBoost 是一種利用用戶點擊行為來提升、降低或加強網頁搜索結果排名的方法。
Nayak 提到 NavBoost 大約從 2005 年起就已經存在,並且一直以來都在使用過去 18 個月內的點擊數據進行分析。這個系統最近進行了更新,現在會使用過去 13 個月的數據來提供網頁搜尋結果。
在信息檢索中,使用點擊次數來衡量成功是一種最佳做法。我們也清楚 Google 現在採用的是由機器學習驅動的算法,而這些算法需要依賴響應變量來提升表現。
即使有這麼多令人震驚的證據,但由於 Google 發言人提供了錯誤的信息,加上搜尋行銷領域中許多文章毫無批判性地重複 Google 的公開聲明,因此 SEO 社區對此依然感到混淆。
Gary Ilyes 多次討論過有關如何測量點擊的問題。有一次,他強調了 Google 搜尋工程師 Paul Haahr 在 2016 年 SMX West 大會上提到的現場實驗觀點,並表示『將點擊數直接用於排名是錯誤的。』

後來,他在自己的平臺上公開貶低 Rand Fishkin,稱『停留時間、點擊率,不管 Fishkin 提出的新理論是什麼,那些通常都是胡編亂造的廢話。』
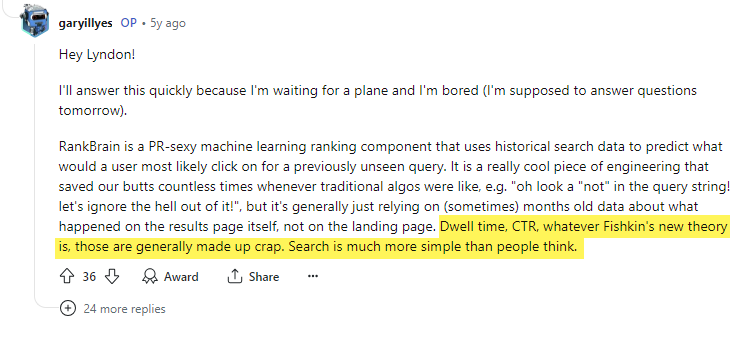
事實上,NavBoost 內部有一個完全專注於處理點擊信號的模組。

這個模塊總結中提到,它被定義為“擲骰子的點擊與曝光信號”,屬於一種排名系統。
我們可以看到,像壞點擊、好點擊、持續時間最長的點擊,以及未經處理(即未壓縮)的各類型別,都會作為評估指標。
badClicks和goodClicks:衡量使用者在搜尋結果中的點選行為,如果滿足需求不再點選其他結果,就是加分,反之減分。lastLongestClicks和lastGoodClicks:衡量點擊是否隨著時間衰減,考慮有時效。
根據 Google 的『基於位置顯著性評分本地搜尋結果』專利,『壓縮是一種防止某個強烈信號壟斷其他信號的功能』。
換句話說,這些系統會對點擊數據進行標準化處理,以避免因為單一點擊信號而造成的不當影響。
很多這些基於點擊的測量方法,也出現在另一個與索引信號有關的模塊中。其中一項指標是某份文件被『最後一次有效點擊』的日期。這意味著,內容衰減(即隨著時間推移而導致的流量下降)也與排名頁面在搜索引擎結果頁面(SERP)中未能獲得預期點擊數有關。
另外,文件中把用戶看作是投票者,他們的每次點擊都被記錄成一次投票。系統會計算不正確的點擊次數,並根據不同國家和設備來分類這些數據。他們也會記錄用戶在一次搜尋中哪個結果被點擊得最久。
所以,不只是要完成搜尋並點擊結果,用戶還需要在該頁面上停留相當一段時間。
多方消息指出,NavBoost 已經成為 Google 排名算法中的重要排名訊號之一。在洩露的文件中,“Navboost”這個詞被提及了 84 次,有五個模組的標題中都包含了 Navboost。
p.s. 其中並沒有看到點擊率、停留時間的參數
證據相當明確,幾乎可以肯定 Google 將點擊和點擊後行為作為其排名演算法的一部分。
“There is no Sandbox”

Google 的發言人強調,不會因為網站的年齡或缺乏信任度而將其放入所謂的“沙盒”。在一條已被刪除的推文中,John Muller 回答了關於網站多久能夠獲得排名資格的問題,他說:“不存在什麼沙盒。”

但 PerDocData 模組的文檔提到了一個叫做 hostAge 的屬性,它主要是用來隔離新的垃圾內容。
“We don’t use anything from Chrome for Ranking”

Matt Cutts 曾經說過,Google 並不會將 Chrome 的數據用於自然搜尋結果中。最近 John Mueller 再次確認了這個觀點。
但 ChromeInTotal 這個參數,表示網站在 Chrome 的整體瀏覽量(以此瞭解網站的訪問規模)。

有一個模塊是用來評估頁面品質得分的,這裡包含了從 Chrome 瀏覽器獲取的站點級別瀏覽數據。另外還有一個看起來是用於生成網站 的模塊,也同樣具備和 Chrome 有關的屬性。

2016 年 5 月,一份有關 RealTime Boost 系統的內部洩露報告指出,Chrome 的數據已經被用於搜尋功能。
關注自然搜尋流量的行銷人員必讀重點
非 SEO 專業的朋友只需要看到這個部分即可,此部分嘗試總結這次洩漏涵蓋的時期:2005-2023 年間,Google 的許多演變,但不限於洩漏的確認元素。
1. 品牌比任何其他事物都重要
Google 擁有多種技術來識別各種 Entity,並對其進行排序、排名和過濾。這些 Entity 包括品牌(例如品牌名稱、官方網站及相關社交媒體帳號等)。
根據我們與 Datos 進行的點擊流研究顯示,Google 越來越傾向於優先排列那些主宰網絡的大型知名品牌,而非小型獨立站點或企業。
2. 經驗、專業知識、權威性和可信度(“E-E-A-T”)可能不像一些 SEO 專家所想的那樣直接重要
在找到的洩漏信息中,唯一提到專業知識的是一段關於 Google Maps 評論貢獻的小註解。
至於 E-E-A-T 的其他部分,不是被掩蓋了,就是表達得很間接或用不易辨認的方法標示出來,又或者它們只是與 Google 關注和使用的東西有關,但並非排名系統中的具體因素。
根據 Mike 的文章所述,洩露的文件表明 Google 能夠識別出作者(Author)並將其視為系統中的一部分。
在線上建立個人影響力的作者,確實有可能因此獲得在 Google 搜尋結果中的排名提升。
在排名系統中,到底是哪些因素組成了“E-E-A-T”,以及這些因素的影響力有多大,目前還沒有定論。Rand 有點擔心 E-E-A-T 有 80% 是宣傳噱頭,而只有 20% 是真正的實質內容。
魁:我的認知是 Entity 也是 E-E-A-T 的一環,有可能是文件的內容讓人感覺演算法側重 Entity,也可能是洩漏的文件沒有提及 E-E-A-T 太多。
根據 HouseFresh 最近的一篇廣受關注的文章,有很多知名品牌在 Google 搜尋中的排名非常高,但它們並沒有太多的經驗、專業知識、權威性或可信度。
3. 當用戶在瀏覽網站時有明確的導覽意圖(以及由此產生的行為模式)時,內容和連結的重要性就會降低
舉例來說,許多在西雅圖地區的人搜尋「雷曼兄弟」,並滾動到搜尋結果的第 2、3 或 4 頁,直到找到雷曼兄弟舞台劇的劇院列表,然後點選該結果。
很快地,Google 會學到那個地區搜尋那些詞語的使用者想要什麼。
即便維基百科上有關雷曼兄弟在 2008 年金融危機中的角色的文章,花費大量精力進行連結建設和內容優化,也很難超過西雅圖劇院觀眾所表現出的用戶意圖信號(這些信號是通過查詢和點擊來計算的)。
如果我們把這個例子應用到更大的網絡和搜尋範圍上來看,只要你能在目標地區吸引足夠多的人來訪問你的網站,就有可能不需要依賴傳統的 SEO 方法,比如連結、錨文本或優化內容等。
NavBoost 的影響力以及用戶的搜尋意圖,可能是 Google 排名系統中最重要的因素之一。一如 Google 副總裁 Alexander Grushetsky 在 2019 年發給高層管理人員(包括 Danny Sullivan 和 Pandu Nayak)的一封電子郵件中提到的:
我們已經了解,有時在某些特定的衡量標準下,單一信號的效果可能會超過整個大型系統。
舉個例子,我很肯定單靠 NavBoost 在點擊率方面(甚至可能在精度和效用指標上)表現得比其他排名方法要好。(順帶一提,Navboost 團隊之外的工程師以前也對於 Navboost 的強大感到不滿,因為它總是“瓢竊”了成功。)
如果你想要進一步確認,可以參考 Google 工程師 Paul Haahr 的詳細履歷,其中:
我是負責基於日誌排名專案的 Manager。我們團隊目前專注在四個主要領域:(1)NavBoost。這已經是 Google 最重要的排名信號之一,我們現在正在致力於自動化生成新的 Navboost 數據;
4. 傳統的網站排名因素,如 PageRank、錨文本(根據連結中的文字進行主題 PageRank)以及文本匹配等,這些年來其重要性一直在下降。但是頁面標題依然非常重要。
Mike 的精彩分析揭示了一個重要發現,PageRank 在搜尋引擎的索引和排名中依然重要,但它已經從 1998 年最初的論文有所改進。
5. 對於大部分中小型企業和新進的創作者或出版商而言,在你們建立起信任度、滿足導覽需求並在廣泛受眾間獲得良好聲譽之前,SEO 的效果可能不會太理想。
SEO 是一個大品牌、熱門網站的競爭遊戲。
Rand 認為,在接下來的幾年裡,除非 SparkToro 在其行業中變得更加知名且受歡迎,有更多人搜尋和點擊,不然這個網站即便有原創內容,也仍會被那些已經存在超過 10 年的聚合平台和出版商排在後面。
魁:希望 AI Overview 的遊戲規則可以打破這個現況。抓取資料時能更多的抓到那些富含 E-E-A-T 的內容。
再來就是 SEOer 們才需要關注的細節啦。
GOOGLE 排名系統的架構
Google 演算法是由一系列微服務組成的,這些微服務在運行過程中會對許多特徵進行預處理,然後生成搜尋結果頁面(SERP)。每個單獨的系統代表一個『排名訊號』,也就是 Google 經常提到的 200 個排名訊號的來源。
在 Jeff Dean 的 Building Software Systems at Google and Lessons Learned 演講中,他提到 Google 在早期會將每個查詢分配給 1000 台機器來處理,並且能夠在不到 250 毫秒的時間內做出回應。以下是系統架構抽象的早期版本圖。
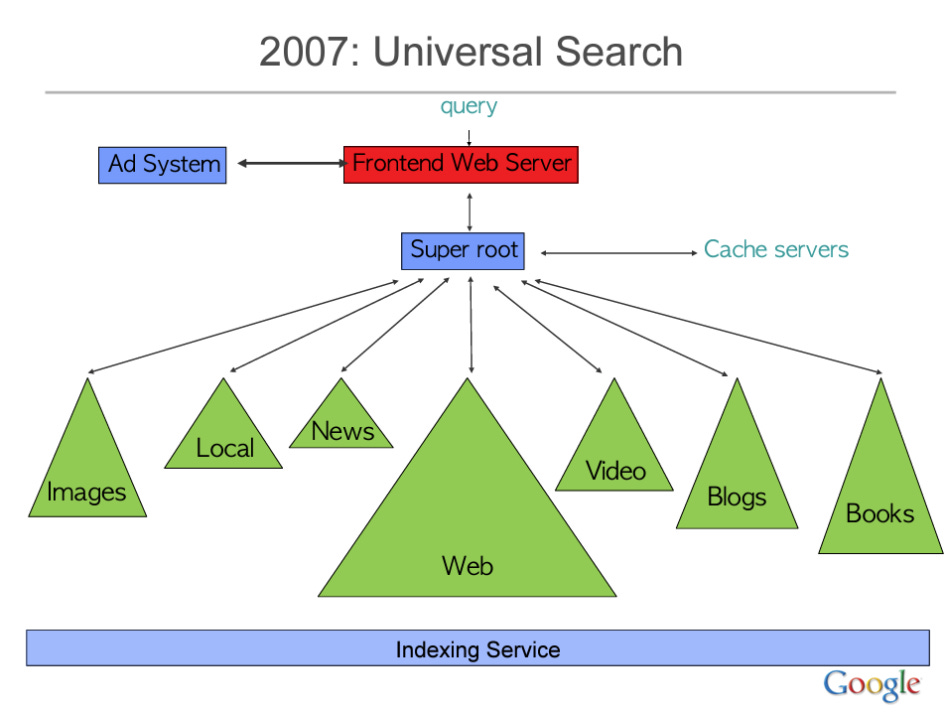
著名的研究工程師 Marc Najork 最近在他的生成式信息檢索演講中展示了 Google 搜尋系統的一個簡化模型,並介紹了其 RAG 系統(也被稱為 SGE 或 AI Overview)。該圖表描述了一系列不同類型的數據庫和伺服器,它們負責處理搜索結果中的各種層面。

Google 的告密者 Zach Vorhies 洩露了一張 PPT,展示了 Google 內部各種系統之間的關聯以及它們的內部名稱,在文件中提到了其中的一些系統。
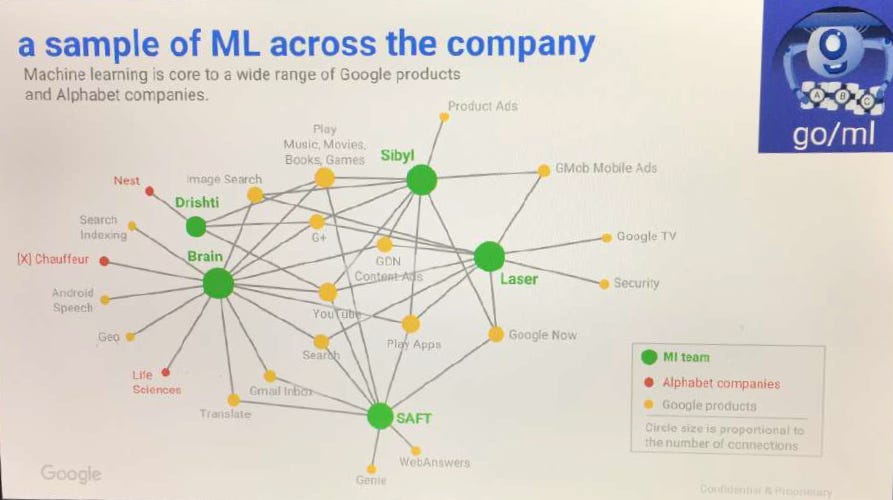



以下是排名系統的各個子系統
Crawling 爬行
Trawler– 是一種網頁抓取系統。它包含了一個抓取隊列,可以控制抓取速度,並且能夠了解網頁更新的頻率。
Indexing 索引
Alexandria– 核心索引系統。SegIndexer– 將檔案分層到索引中的系統。TeraGoogle– 是一種專門為長期存放在硬碟上的文件設計的二次索引系統。
Rendering 渲染
HtmlrenderWebkitHeadless是一個用來渲染 JavaScript 頁面的系統。有趣的是,它的名稱取自 Webkit 而非 Chromium。文檔中有提到 Chromium,因此推測 Google 可能最初使用的是 WebKit,但在 Headless Chrome 推出後改用了它。
Processing 處理中
LinkExtractor– 從頁面中提取連結。WebMirror– 用於管理正規化和重複的系統。
Ranking 排名
Mustang – 主要的計分、排名和服務系統
Ascorer – 在任何重新排名調整之前對頁面進行排名的主要排名演算法。
NavBoost - 是一種基於用戶點擊記錄來進行結果重新排序的系統。
FreshnessTwiddler– 基於新鮮度的檔案重新排序系統。WebChooserScorer– 定義用於片段評分的特徵名稱。
Serving 服務
Google Web Server– GWS 是 Google 用來與前端進行互動的伺服器,它負責接收並展示給用戶看的數據。SuperRoot– Google 搜尋的大腦 – 它負責向 Google 的伺服器傳遞訊息,同時管理用於重新排序和展示搜尋結果的後續處理系統。SnippetBrain– 生成結果摘要的系統。Glue– 能夠根據用戶行為來匯總各種結果的系統。Cookbook– 用於生成訊號的系統,有跡象表明值是在執行階段建立的。
SEOer 們來漲漲知識了
什麼是 Twiddlers ?
Twiddlers 是一種在主要 Ascorer 搜尋算法完成後執行的重新排序功能。其運作方式有點像 WordPress 裡面的過濾器和動作,Twiddlers 能夠修改文檔在信息檢索中的得分,會在結果展示給用戶前進行最後調整。
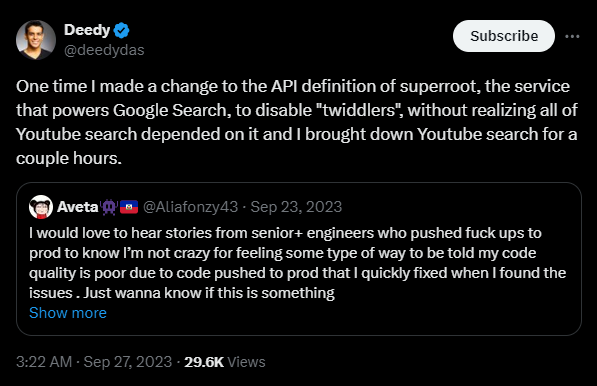
前 Google 員工表示,Twiddlers 在各種 Google 系統中都非常重要。
『有一次,我修改了 superroot 的 API 定義。superroot 是支撐 Google 搜尋功能的服務。我當時禁用了 "twiddlers" 功能,但沒想到這會影響到整個 YouTube 的搜尋系統,導致 YouTube 搜尋中斷了幾個小時。』

Twiddlers 能夠設置類別約束,也就是說,可以透過限定結果種類來增加多樣性。舉例來說,作者或許會選擇在某個搜尋引擎結果頁(SERP)中僅顯示三篇部落格文章,這有助於釐清當前頁面格式下是否還有機會提升排名。
當 Google 提到像 Panda 這樣的更新並非核心算法的一部分時,通常表示它最初是以 Twiddler 的形式啟動,用來進行重新排序的提升或降級計算,之後才被整合到主要評分系統中。
Panda 算法作為 Twiddler,可以作為重新排名的提升或降級計算,然後可能會被移動到主要的評分功能中。類似於伺服器端渲染和客戶端渲染之間的區別(不同階段的處理 & 整合)。
具體來說,Panda 算法會分析用戶行為(例如點擊、互動等)和網站的連結根域名(backlinks),並根據內容品質和高品質連結的數量為每個網站分配一個「網站品質分數」,這個分數會影響網站的排名。如果網站得分高,則獲得提升;反之則可能會被降級。
我們可以推測,所有名稱以 Boost 結尾的函數都在使用 Twiddler 框架進行操作。以下是文件中列出的一些 Boosts:
NavBoost
QualityBoost
RealTimeBoost
WebImageBoost
貓熊的運作方式
(這個部分有點小複雜不一定要懂,想跳過可以跳過)
Panda 在 Amit Singhal 的領導下推出。他堅決反對使用機器學習,因其可觀察性有限。
實際上,有許多專利針對 Panda 的網站品質進行研究,但我特別想提到的是那項名不見經傳的『排名搜尋結果』專利。
這項專利說明了 Panda 其實比我們預期的要簡單得多,它主要是通過分析用戶行為和外部連結等分佈信號來建立一個評分調整工具。而這個調整工具可以應用在不同層次,包括域名、子域名或子目錄。
系統會依據獨立連結和引用查詢的數量來產生一個用於資源組的調整因子(步驟 306)。舉例來說,修正因子可以用這個群體中的獨立連結數和參考查詢數的比例來計算。換句話說,修正因子 (M) 可以表達為:M=IL/RQ
在這裡,IL 代表的是針對該資源群體所統計的獨立連結數,而 RQ 則是針對該資源群體所統計的引用查詢次數。
這邊用 ChatGPT 來協助比喻解釋
想像你在學校裡參加了一個「最受歡迎學生」的比賽。這個比賽有兩個評分標準:
獨立投票數(IL):這就像是你從不同班級的同學那裡獲得的投票數。每個班級的同學只能投一次票給你。
參考問題數(RQ):這就像是老師們問了多少次「誰是最受歡迎的學生?」這個問題。
現在,系統會根據這兩個標準來計算一個「修改因子(M)」,這個因子決定了你在比賽中的最終得分。計算方法是把你獲得的獨立投票數除以參考問題數。
系統會根據你獲得的獨立投票數和參考問題數來計算一個修改因子,這個因子決定了你在比賽中的最終得分。這樣的計算方式可以幫助確保評分的公平性和準確性。
獨立連結基本上指的是我們通常理解的根域名連結,而引用查詢則要更為複雜一些。以下是專利中對這些概念的定義:
針對某一類別資源的參考查詢,可以是之前提交過並且已經歸類為屬於這些資源的一次搜尋請求。
要把某個之前提交過的搜尋查詢歸類到某一群資源中,可以這樣做:確認這個搜尋查詢裡面有一些詞彙,這些詞彙已經被認為是和那群資源相關聯的。
這邊用 ChatGPT 來協助比喻解釋
想像你在學校圖書館工作,負責幫助同學們找到他們需要的書籍。圖書館裡有很多不同的書籍,這些書籍被分成不同的類別,比如「科學」、「文學」、「歷史」等等。
參考查詢
參考查詢:這就像是同學們之前提交的搜尋請求,這些請求已經被分類到特定的書籍類別中。例如,有同學之前搜尋過「愛因斯坦的理論」,這個搜尋請求被分類到「科學」類別中。
分類過程
分類過程:當你要把一個新的搜尋請求分類到某個書籍類別時,你會檢查這個搜尋請求中是否包含一些特定的詞語,這些詞語可以幫助你確定這個請求應該屬於哪個類別。例如,如果新的搜尋請求中包含「愛因斯坦」這個詞,你就可以判斷這個請求應該屬於「科學」類別,因為「愛因斯坦」這個詞已經被確定是與「科學」類別相關的。
具體解釋
參考查詢:對於某一組資源(例如「科學」類別的書籍),參考查詢可以是之前提交過的、已經被分類為與這組資源相關的搜尋請求。
分類過程:將一個之前提交過的搜尋請求分類為與某一組資源相關,這個過程包括:確定這個搜尋請求中包含了一個或多個已經被確定為與這組資源相關的詞語。
簡單來說,這段話的意思是:
當系統要把一個新的搜尋請求分類到某個資源群組時,系統會檢查這個請求中是否包含一些特定的詞語,這些詞語已經被確定是與這個資源群組相關的。這樣,系統就可以更準確地將搜尋請求分類到正確的資源群組中。
現在我們已經獲得這些檔案,很明顯,參考查詢是來自 NavBoost 的查詢。


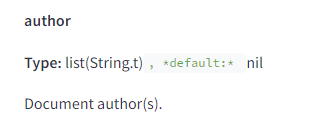
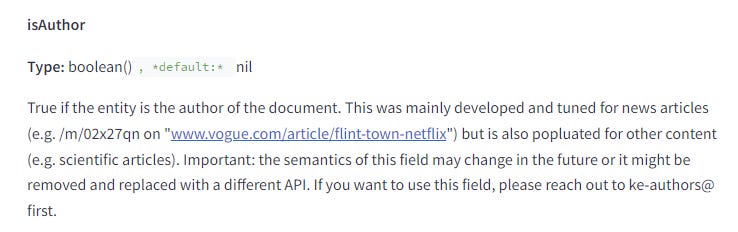
作者(author)是一個明確的特徵
Google 會將與文件相關的作者信息以文字形式清楚地保存下來。

他們也在檢查頁面上的某個 Entity 是否同時是這個頁面的作者。

Demotions 降級
洩漏文件中討論了一系列的演算法降級,除了 Panda 外。Demotions 是指在 Google 搜尋算法中,某些特定的因素會導致相關頁面或連結的排名被降低:
錨點不一致 – 如果一個連結與與它所指向的網站內容不符,那麼這個連結在排名計算中會被降低權重。就像我之前提到的,Google 會檢查每個連結兩端是否具有相關性。
SERP 降級 – 這是一種根據搜尋引擎結果頁面(SERP)中觀察到的一些因素,來判斷是否需要將某個網頁降級的信號。它暗示了用戶可能對該網頁感到不滿,而這種不滿通常是通過點擊行為來測量的。
導覽降級 – 這可能是一種針對那些在導覽設計或用戶體驗上表現不佳的頁面的懲罰措施。
精確匹配域名降級 – 在 2012 年底,Matt Cutts宣布精確匹配域名將不再享有過去那樣的高價值。這些域名被降權是因為一項特定的機制。
產品評論降級 – 雖然沒有詳細資訊,但這項變動被標註為降級,可能是因應 2023 年最新的產品評論更新。
位置降級 – 有證據顯示,“全球性” 頁面和 “超全球性” 頁面可能會被降低排名。這意味著 Google 會嘗試將網頁與特定地點關聯,並根據該地點來調整它們的排名。
色情降級 – 這個很明顯。
其他連結降級
連結看起來還是很關鍵的
索引層級影響連結價值

有一種名為
sourceType的指標,用來展示網頁被索引的位置與其價值之間的某種關聯性。簡單說明一下背景,Google 將其索引分成不同層級:其中最重要且經常更新和訪問的內容會存放在快閃記憶體中。
較不重要的內容存儲在固態硬碟上。
那些不常更新的資料則放在傳統硬碟裡。
基本上,這意思是說層級越高,連結就越有價值。那些被認為 “新鮮” 的頁面也通常被視為高品質。
因此,你應該確保連結來自於那些要麼是最新更新的,要麼就是位於頂端層級的頁面。
這可以部分解釋為什麼從高流量的網頁和新聞網站獲得連結,能夠提升我們的搜尋引擎排名效果。
垃圾連結的傳播速度信號

Google 用
phraseAnchorSpamDays來識別垃圾連結,識別垃圾連結的頻率、數量、起始時間,識別後會忽略這些垃圾連結。這些數據可以用來比較一個網站的連結發現基線(baseline)與當前趨勢。如果發現某個網站的連結數量突然激增,Google 可以選擇不計算這些連結,從而防止垃圾 SEO 攻擊對網站排名的負面影響。
Google 在分析連結時,只會考慮特定 URL 的最近 20 次變更
Google 的檔案系統可以像 Wayback Machine 一樣,隨著時間推移保存網頁的不同版本。這就是為什麼你無法僅僅只是把一個頁面轉址到一個無關的目標,然後期待連結權重會隨之轉移。
這些文檔進一步支持了這一想法,表明他們保存了所有頁面歷史上的每一次變動。

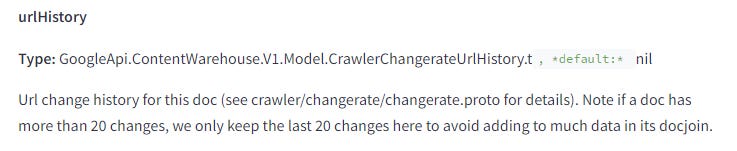
在使用 DocInfo 檢索數據以進行比較時,他們僅會考慮該頁面最近的 20 個版本。這可以幫助你明白,在 Google 上要達到一個全新的開始,你需要更改和重新索引頁面的次數。
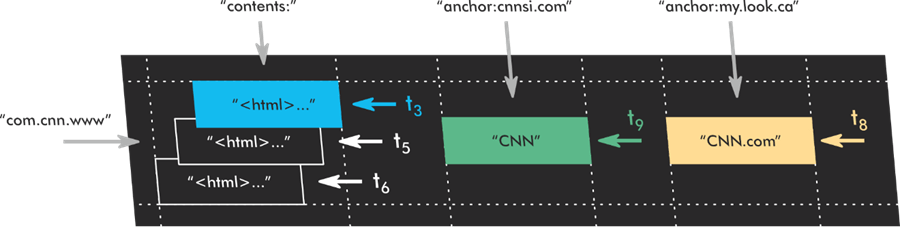


網站首頁的 PageRank 會影響到所有內部頁面

每個網頁在剛上線時的初始 PageRank 都是首頁的 PageRank,直到網頁透過使用者互動或外部連結獲得自己的 PageRank。
可能這個和
siteAuthority在新頁面還沒有計算出自己的 PageRank 之前,被當作替代指標來使用。
首頁信任

Google 會依據對網站首頁的信任度來判斷該外連的價值。
一如既往,你應該專注於連結的品質和相關性,而不是數量。
字體大小會影響關鍵字和連結的效果
Google 會追蹤文件中各個關鍵字術語的平均加權字體大小。
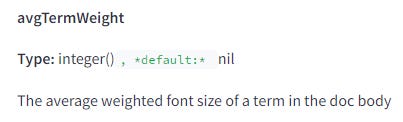
他們對連結的錨文字也做了同樣的處理。


企鵝移除內部連結
在很多涉及錨點的模組中,“本地”通常指的是同一個網站。
droppedLocalAnchorCount這個值顯示有些內部連結未被計入。Penguin 算法可能會忽略來自同一網站內部的某些連結,這些連結不會被計入排名計算中。
完全沒看到有關 Disavow 的任何提及
這可能意味著 Disavow 連結工具的數據與核心排名系統是分離的,並且可能被用來訓練垃圾內容分類器。
這一發現對於 SEO 專業人士來說,意味著他們需要重新考慮如何使用 Disavow 連結工具來優化網站的排名。
網頁文件會被截斷
Google 會計算出現的 Token 數量,並且分析正文中的總詞數和獨特 Token 數量之間的比例。
根據文件說明,Mustang 系統對於每個文檔能處理的 Token 數量有上限。
因此,建議作者們仍然要把最關鍵的內容放在文章開頭。
解釋
詞元數量:詞元是指文本中的基本單位,可以是單詞、標點符號等。Google 會計算文件中的詞元數量來決定是否需要截斷。
唯一詞元數量:這是指文件中不重複的詞元數量。Google 會考慮總詞數與唯一詞元數量的比率來評估文件的品質。
唯一詞元數量(unique tokens)可以決定文章品質,這是因為它能夠反映文章的多樣性和豐富性。
Mustang 系統:這是 Google 的主要評分、排名和服務系統。文件在這個系統中可能會被截斷,以確保處理效率和品質。
短內容以原創性評分

原創內容的評分顯示,即使是較短的文章也能因其獨特性而獲得高分。因此,薄弱的內容(thin content)不一定取決於篇幅長短。
相反地,也有一個關鍵字堆砌分數。
網頁 Title 跟關鍵字匹配依然重要

文件指出存在一個名為 titlematchScore 的指標。說明中提到,Google 依然非常看重頁面標題與搜尋查詢之間的匹配度。將目標關鍵字放在首位仍然是正確的做法。
Meta Title 及 Des 沒有字數限制

值得注意的是,Gary Ilyes 提到 SEO 專家自行設定了中繼資料(meta data)的最佳字元數量。在這個研究資料集中,其實並沒有針對頁面標題或摘要長度進行任何具體測量。我在文件裡發現唯一有關字元計數的方法是 snippetPrefixCharCount,看起來它主要用於決定哪些內容能夠成為摘要的一部分。
這進一步證實了多次測試的發現:
雖然冗長的頁面標題不利於吸引點擊,但在提升搜尋排名方面卻效果良好。
日期非常重要
Google 對於提供最新的搜尋結果非常重視,他們不斷努力將日期和網頁內容連結起來。
bylineDate– 這是頁面上明確設定的日期。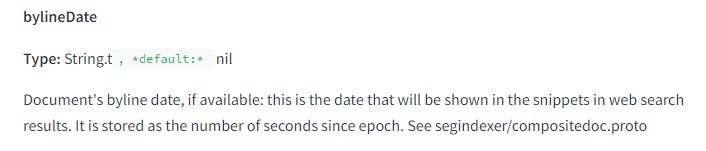
syntacticDate– 這是從 URL 或標題中提取的日期。
semanticDate– 這是從頁面內容中得出的日期。
你應該為內容設定一個統一的日期,並確保這個日期在結構化資料、頁面標題和 XML 網站地圖中都保持一致。如果 URL 中的日期與頁面其他部分顯示的日期不一致,可能會影響內容的表現效果。



使用網域註冊資訊
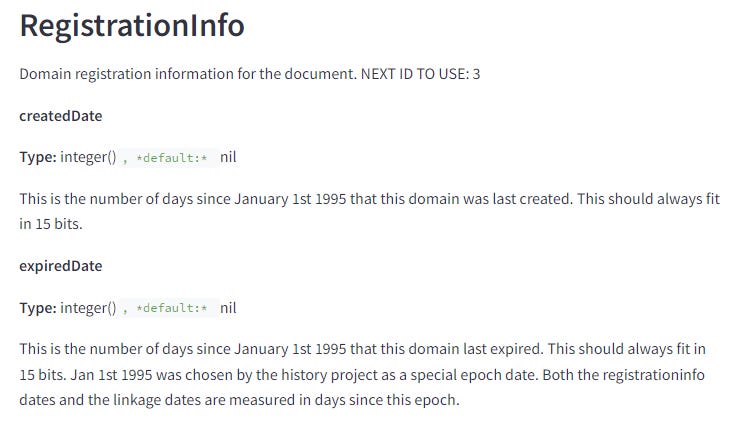
長期以來,有人認為 Google 身為域名註冊商會對搜尋算法產生影響。現在,我們可以確認這很可能是事實,他們確實保存了最新的註冊資訊。
正如之前討論過的,這個機制很可能是為了對新內容進行沙盒測試。此外,它還可以應用於那些所有權發生變更的已註冊域名。我猜想,由於近期引入了針對過期域名濫用的新垃圾內容政策,因此這一機制的重要性得到了提升。
以影片為主的網站會有不同的處理方式

當一個網站有超過 50% 的頁面都包含影片時,它就會被認定為主要提供影片內容的網站,並且會採取不同的管理方式。
Your Money Your Life 有特別的評分標準
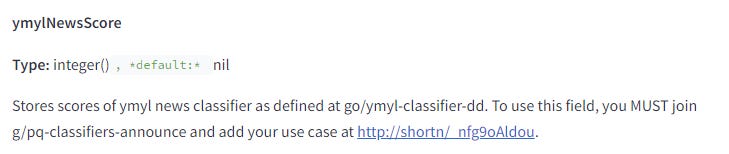
根據文件說明,Google 擁有能夠為 YMYL(你的金錢或你的生活)健康和新聞內容打分的分類系統(分類器)。
他們也會對一些從未出現過的“邊緣查詢”進行預測,來判斷這些查詢是否屬於 YMYL 類型。

總之,YMYL 的核心在於塊級處理(chunk level),這意味著整個系統依賴於嵌入(Embeddings)技術。
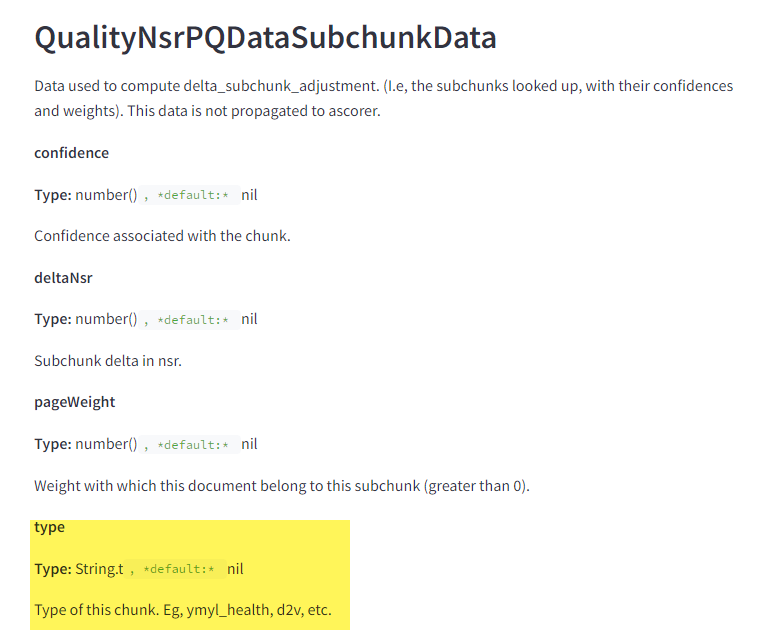

有黃金標準檔案
目前還不知道這到底代表什麼,不過描述中提到的是“人工標記的文件”和“自動標記的註釋”。猜測這或許和品質評分有關,但 Google 表示品質評分並不會影響搜尋結果排名。因此,我們可能永遠無法得知真相。


網站嵌入(Embeddings)技術被用來評估一個頁面的內容是否與主題相關
siteFocusScore用來衡量網站專注於單一主題的程度。而 site radius 則用來測量頁面相較於核心主題的偏離範圍,這是基於為該網站生成的 site2vec 向量計算得出的。魁:透過 siteFocusScore 應該會先區出分垂直型網站(特定專業)或廣泛性網站(新聞媒體、生活居家)
Google 目前正在對網頁和網站進行向量化處理,並通過比較網頁與整個網站的嵌入來判斷該網頁是否偏離了主題。
魁:現在的 AI Overview 也是用相同的方式在抓取資料來源,但如何被抓值得研究(base E-E-A-T、cos 值相近但又不會太近等等的)
Google 可能會故意打壓小型網站
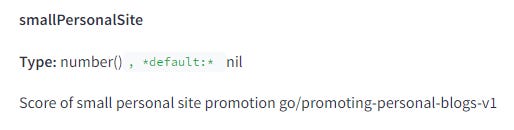
Google 有一種特殊標記,用來識別某個網站是否屬於“小型個人網站”。雖然對此類網站並沒有具體定義,但 Google 或許可以透過這個來提高或降低這些小型個人站點的排名。
魁:資訊太少,這也可以變成幫助小網站的工具(如果 Google 願意的話🥹),但是證據顯示目前還是比較有利大品牌的
有大量證據表明,小型網站正在失去大部分流量,而且 Google 向這些長尾網站提供的流量也越來越少。


其它洩漏中的新發現
Baby Panda 不是 HCU
Baby Panda 指的是一個較舊的系統,而不是 Helpful Content Update。
但 HCU 表現出與熊貓相似的特性,並且可能需要類似的特徵來改善以進行恢復。
技術洩漏可以追溯到兩年前

或許存在一種評估生成式 AI 內容的努力程度的分數系統

Google 正在研究如何衡量創作內容時投入的努力程度。根據目前的定義,我們不清楚是否所有內容都會被大語言模型評估,還是只有那些他們懷疑是用生成式 AI 創作的內容才會被評分。
Google 衡量了頁面更新的重要性

頁面更新的重要程度會影響到該頁面的抓取次數以及是否被索引。過去,只要你修改一下頁面的日期,就可以讓 Google 認為你的內容是新的,但現在這個功能顯示出,Google 希望看到的是對於內容有實質性的重大更新。
在 Penguin 演算法中,基於之前的歷史連結來對頁面進行保護

Penguin 的某些頁面因其連結記錄而被視為受保護。
這一點,再加上連結增長速度的信號,可能可以解釋為什麼 Google 堅決認為使用連結進行的負面 SEO 攻擊是無效的。
有害的反向連結確實存在

我們常聽到所謂的“有害反向連結”其實只是為了推銷 SEO 軟體而提出的一個概念。但事實上,文件中確實存在一種名為
badbacklinksPenalized的特性。
有一個 Blog 抄襲分數

這個指標很可能是用來衡量部落格文章內容重複程度的。
在
BlogPerDocData模組裡,有一個名為copycat的分數,雖然它沒有明確的定義,但卻和docQualityScore有關聯。
提及(Mention)非常重要

儘管還沒看到任何證據顯示「提及」會被當作連結來處理,但確實有許多討論是關於「提及」和實體之間的關係。
這進一步證明,在內容策略中加入以 Entity 為核心的方式是非常有價值的。
Googlebot 比我們想像的更強大

Googlebot 不只是能進行 GET 請求,根據文件說明,它也能處理 POST、PUT 和 PATCH 等請求。
衡量使用者生成內容(UGC)的「投入」多寡

使用用戶生成的內容(UGC)是一種有效且可延展的方法,可以增加頁面的內容數量,同時提升其相關性和更新頻率。而
ugcDiscussionEffortScore顯示 Google 會單獨評估這些 UGC 的品質,而不是把它們與主要內容混為一談。
Google 會檢測頁面的商業性
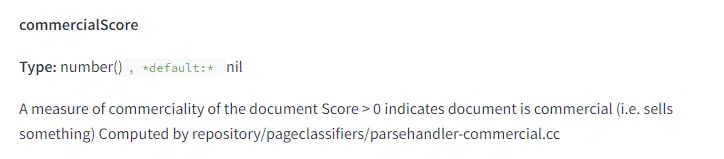
除了從使用者意圖來衡量商業性外,Google 也是依據這種方法來給文件打分,並且利用此方法防止某些頁面出現在具有資訊性需求的查詢結果中。
從描述來看,評分似乎被簡單地當作二元處理。
魁:這會影響內容以不同的意圖出現在 SERP 上。
人們用洩露的文件做的酷事情
Natzir 的 Google 排名特徵模組關係:Natzir 使用 Streamlit 開發了一款網絡圖視覺化工具,用來展示不同模組之間的相互關聯。

WordLift 的 Google 洩漏報告工具:Andrea Volpini 開發了一款 Streamlit 應用程式,你可以使用它來向文件提問並生成相應的報告。










SEO 策略上需多留意的面向
內容需要更集中(領域相關性)
我們現在知道,Google 會利用向量嵌入技術來評估某個頁面與你討論的其他內容之間的相關性。
這意味著,要想成功地深入探討上層漏斗的內容,如果沒有系統性的擴展計劃或具備相關專業知識的作者,是非常困難的。
鼓勵你的作者在網上發表內容時,不斷提升自己的專業水平,並珍惜他們的署名,就像對待黃金標準一樣。
多關注點擊指標
SEO 和用戶體驗需要更緊密地合作
頁面標題可以設置成任意長度
如果在標題中加入更多與關鍵字相關的元素,可以增加點擊率。這是因為當 Google 重新生成標題時,有更多內容可供選擇。
專注於來自有流量網站的連結相關性
我們發現,從在索引中排名較高的頁面獲取的連結價值更大。那些點擊率較高的頁面,更有可能被存儲在 Google 的快閃記憶體裡。
Google 對內容的相關性非常看重,因此我們應該不再一味地追求連結的數量,而是要把注意力集中在內容的相關性上。
優先選擇原創內容,而非冗長的形式
確保與頁面相關的所有日期一致
使用舊域名時要格外小心
如果你想要利用一個舊域名,光是購買它並把新的內容放到原有的網址上是不夠的。你必須用系統化的方法來更新這些內容,才能慢慢讓 Google 忘掉之前儲存的信息。
魁:記得 20 次歷史快照版本嗎
參考資料:
The Google API Leak Should Change How Marketers and Publishers Do SEO
Secrets from the Algorithm: Google Search’s Internal Engineering Documentation Has Leaked
How SEO moves forward with the Google Content Warehouse API leak
Leaked Google Search API Doc Aggregation of Analysis, Tools and Resources [by Aleyda]
好复杂啊,以前好像没有这么复杂,都是一点一滴地进化而来的。
太专业了!点赞