

裝了 LLM 的 Google SGE 將如何演變,使用者行為又會如何改變
來聊聊當 Google 搭載了大型語言模型後會怎麼進化,我們的搜尋行為是否會有不同。


卷首語
禮拜日頭痛九點多就直接晚安了,所以拖稿了幾天。
最近寫程式的時間越來越多了,學會佈署程式上 Azure 了,希望今年可以寫個可以收費的簡單小軟體,實現被動(微)收入!
總統大選前中後都會有一些奇怪的謠言或影片出現在社群媒體上,製作並散播這些 10 幾秒到 1 分鐘的短影片很簡單,但驗證要花很長篇幅來終止謠言,所以大家一定要謹慎接收資訊,不要聽風就是雨。
我們會克制身體涉入過量的垃圾食物,但是也請小心,避免過量的資訊垃圾(像是短影片)進入我們的腦中,影響心智。
正文開始
平常文章都是業外興趣看看書、研究一下 LLM 工具,今天從本業 SEO 的角度出發聊聊 Google 今年 SGE 『可能』會怎麼改變使用者行為。
只是個預測有理就看看,覺得邏輯不太對也歡迎留言討論交流。
(文章圖片引用自我在 isearch 上的演講內容)
1. 傳統搜尋行為

請大家思考一下,平常在搜尋 Google 時,我們都如何進行搜尋的?以上圖這個問題為例:『心理學和經濟學如何在決策中相互作用』
我們都知道,像這樣又長又複雜的問句只要放在 Google 裡面,通常不會出現什麼好的結果。

因為傳統 Google 理解語意的能力有限,對於短語句還算可以,一旦問題複雜度上升 Google 就無法理解使用者的意圖了。
於是,我們在搜尋時會分成幾個步驟:
先打碎我們準備搜尋的語句,變成多個小且去脈絡化的關鍵字/句
然後分別搜尋這些關鍵字
最後重新整理這些零散的資訊
這就是使用者在傳統搜尋引擎 Google 上所做的事情,這邊也請讀者們回想一下自己的搜尋過程,是不是一個先『去脈絡化』後,各別蒐集資訊再組合起來。
2. 可以理解語意的模型

ChatGPT,是 2023 年最廣為人知的 AI 模型,但其實這樣說不對,因為大型語言模型 LLM 只是 AI 眾多分支的其中一種,但他在去年被當做 AI 的代名詞。
原因就在其強大的『語意理解』 能力,過往的問答機器人往往只能回答預先設定好的答案,但是從來沒有在非專業對談中,還能如此應答如流的機器人。
這邊不究其原理,但是要強調 LLM(大型語言模型)最強大的一項能力就是『理解語意』這件事,跟一般人一樣,相同的資訊下 ChatGPT 對於同一句話的理解程度不亞於一般人。
要知道過往 Google 也有在 AI,其中一個方式就是透過使用者提供的『結構化資料』來訓練,對於程式來說,非結構化的資料很難理解,但是當我們給出對應資料時,程式能夠更好地理解我們的資訊。

而結構化的資料也能更方便用來訓練 AI 理解特定事物,與此同時,Google 也會提供『複合式摘要』來獎勵使用者,藉此提高網站的曝光點擊。
複合式摘要就是有時候會看到 Google 搜尋結果頁上,某幾個排名上資訊展示起來特別不一樣的地方,通常就是 Rich Snippet(這樣解釋稍微不精準,不過對於大部分讀者比較好理解)。像是下圖這個星評,是不是特別吸引人。

Google 很聰明,善於用各種獎勵讓使用者和網站管理員提供資料讓 Google 進行 AI 訓練,多留心也許你也能在某個 Google 的產品發現。
但是結構化資料,我們可以填寫的對應欄位叫 entity,充其量只有 1400 多種,但 GPT-4 用了千億級別的神經元,在訓練上可見兩者能力的差異性。
(其實這樣比較並不正確,但是透過這個方式可以更直觀認識兩個系統在語意理解能力上的差異)

3. 不再盲人摸象:當語言模型安裝到 Google 上

請看上圖,以往我們搜尋的過程,就像收集大象每個部位的資訊,然後再整理成一個完整的大象圖,俗稱盲人摸象。
但前面說了,語言模型可以理解語意的情況下,搜尋可以自動被拆分成好幾個不同的關鍵字,再透過檢索系統抓出特定的資訊,將內容合成特定資訊。
這邊以 Perplexity 為例,當我搜尋的內容是『如何在 Azure 上佈署程式』時,這個搜尋引擎會先收集資訊,詢問我想使用哪種程式語言或框架。

然後當我選擇 Python 後,搜尋引擎會將我的問題需求拆成幾個關鍵字進行搜尋,過去這些行為都是使用者需要做的。
可以看到十幾個來源資料一次被整理在一起。
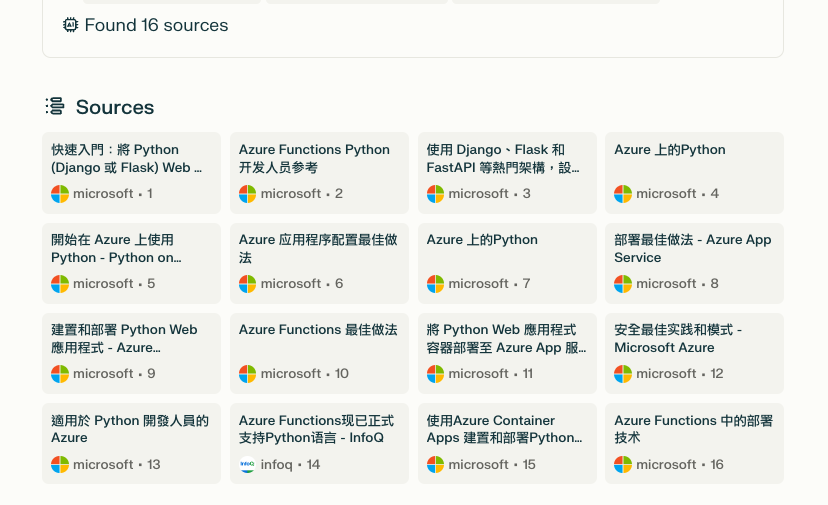
然後整理的動作也由語言模型來進行,人們將能省去更多的資料整理時間。

之所以先用 Perplexity 來 Demo,是因為它是我覺得最接近未來搜尋引擎呈現資訊的樣貌,Perplexity 在檢索資料及拆解使用者意圖這塊很用心在處理,不過大家使用時還是建議以英文作為輸入,只要設定記得繁體中文為主,就會返回中文整理的內容。
Google 的生成式體驗搜尋引擎長這樣:

我目前每天都用它在找我要的資料,基本上它已經在一定程度上取代我使用 Google 的場景,快速蒐集、整理並返回我要的資料,而且還可以用 GPT-4 的模型,有一定的可用性。
不過一個月 20 美元還是有一定的使用門檻,想玩玩看的可以用我的推薦碼,首月會有 10 美元的折扣:https://perplexity.ai/pro?referral_code=TMYQQ5XW
回過頭來說,Google 一直投入 AI 在搜尋引擎上,所以今年所謂的『在搜尋引擎上加入 AI』指的是『脈絡化能力升級』這件事。

4. Google 怎麼偷偷改變你的行為
要知道我們用了十幾年的 Google,搜尋行為早就僵化定型,誰沒事會在 Google 搜尋這麼長的句子返回無用的結果。
所以 Google 開始想了一些招來引導使用者,標籤與篩選器。

當我們搜尋關鍵字後,一定會有對應的搜尋意圖,以『WordPress SEO』為例,相關的意圖可能有『WordPress SEO 教學』、『WordPress SEO 外掛』、『WordPress SEO 檢查清單』等等。
當我們點擊按鈕後,Google 會自動把相關關鍵字給擴充到 Google Search 上,雖然我們按鈕越按越多,一個完整的語句就會出現。

未來 Google 可能還會用其它等等方式,像是『People also ask…』的方式,然後附給你幾個相關的問句進行搜尋。
最終,我們會發現,『ㄝ~~~,原來 Google 可以直接進行長句搜尋了(複雜語句搜尋)』,使用者的搜尋也將從去脈絡化的簡單關鍵字搜尋,變成完整複雜的語句搜尋。
總結
當兩個不同技術結合時,首要考量的是彼此的核心功能為何。LLM 的核心功能在於『理解複雜的語意』,Google 的核心在於『理解使用者意圖並提供高品質內容』。
Google 目前對於語意理解能力非常有限,只要句式過長就難以匹配好的結果;
內容供給端也是如此,大量同質化的內容出現在 Google 第一頁,因為操作 SEO 的方式都差不多,導致越來越少具有獨特觀點、個人經驗或深入的文章出現在第一頁。
語言模型的語意理解能力,加上 RAG 檢索特定資料的能力,恰巧能克服上述這兩項問題,所以 Google 從去年開始就積極在實驗結合 LLM 的搜尋引擎 SGE。
不過畢竟系統整個大改需要很長一段時間的實驗及調整,目前還是以英語然後美國地區來實驗比較好看到 SGE 的內容,所以我才推薦用看看 Perplexity,體驗一下未來的 Google Search 可能會長怎麼樣。
不過一旦 Google 的 SGE 正式上線,Perplexity 該怎麼面對 Google 巨頭提供的免費搜尋服務,又或者 Google 也會將 SGE 視為一個付費訂閱服務,如同微軟新推出的 Copilot 全家餐,成為 AI 付費訂閱服務。
讓我們繼續看下去。
延伸閱讀: