
如何訓練一個科技島讀的AI機器人(用了20小時65美)
科技島讀一直是我心中第一名的內容,透過實作微調不僅加深原理理解,也能在實作過程中感受到 GPT-4 的強大及人機溝通的重要性。(雖然理想還是 Michael 可以復出,畢竟 AI 不可能取代的了 XD)

前情提要
我是一個程式菜雞(新手),Python 的程度僅是上完一門 hahow 上的 Python 課後兩三年沒再深入練習的程度,但透過 GPT-4 幫我完成了其中許多困難的步驟,可以說沒有 AI 的幫助我肯定沒辦法完成。
重要說明:
1. 感謝布丁說明,就算機器人未公開,但訓練數據仍要取得內容擁有者的同意才可訓練,否則仍有著作權的問題
2. 已向科技島讀的 Michael 徵得訓練同意,並且本文未公開電子報之內容
為什麼做這個機器人
因為開立電子報這幾週都是以寫內容為主,筆者本身也不是程式工程師或是 AI 專業領域人員。但希望透過這個實作讓大家知道,就算是程式新手,在現在這個時代也有機會透過程式創造屬於自己的小產品,甚至訓練一個自己的 AI 機器人。
事前準備
想要訓練一個 AI 機器人,目前最常見的方式有兩個,一個是 Fine-tune(微調),一個是 Embedding(將內容轉換成數學向量)。
但前置動作都是先清理資料,將資料轉成特定格式後,選擇預訓練模型的 API 來串接進行後續動作。
p.s. 預訓練模型就是預先訓練好的模型,這次選用的是davinci-003 的模型。
微調原理:
不需要(或不能)改變預先訓練的模型底層結構,只要在模型的「頂層」加上一些新的層,比如分類器或特徵轉換,就可以讓模型學習到你想要的東西。這樣,你就可以用微調來解決各種不同的問題,而不用從頭開始訓練一個新的模型。
想像預先訓練的模型是一座樓房,底層是建立好的結構,而頂層則是可以隨時加蓋的空間。在這個空間上,我們可以添加一些新的房間,比如教室(分類器)或圖書館(特徵轉換),讓模型學會我們想要的知識。這樣,就可以用這個樓房來解決各種問題,而不需要另外蓋一棟樓。
分類器是一種機器學習模型,可以將輸入數據分為不同的類別。在微調中,我們可以在預訓練模型的頂層增加一個分類器,讓模型可以將輸入數據分為我們需要的不同類別。
特徵轉換是指將原始數據轉換為一些更有用的特徵,以便機器學習模型可以更好地學習和理解。在微調中,我們可以在預訓練模型的頂層增加一些特徵轉換,以更好地適應我們的任務。
Embedding 原理:
Embedding 就是一種將文字內容轉換成數學向量的技術,從下圖可以看到,當我們將文字轉成數學上的向量(或想像成座標),就可以發現像似的字詞或內容在座標上會很接近(這邊用顏色更好分)。

Embedding 可以比喻成把物品放到一個多維的空間裡。
多維空間是指一個具有多個特徵或屬性的空間。在我們生活中,我們熟悉的三維空間由長、寬、高三個特徵組成。而在機器學習中,多維空間可能包含更多的特徵,例如顏色、形狀、大小等。
以水果為例,我們可以把顏色看作一個維度(如紅、綠、藍等),形狀看作另一個維度(如圓形、橢圓形、長條形等),大小也是一個維度(如大、中、小等)。這樣,我們就能在這個多維空間中用顏色、形狀、大小等特徵來描述和區分不同的水果。
想像一下,我們有一個多層的抽屜櫃,每個抽屜代表一個特徵,而每個物品都可以根據它的特徵放進對應的抽屜裡。
舉例來說,假設我們有一堆水果,每個水果都有顏色、口味和形狀等特徵。我們可以把這些特徵當作抽屜,把水果分門別類地放進相對應的抽屜。這樣,當我們想找一個特定的水果時,只要看它在哪個抽屜裡,就能更快地找到它。而 Embedding 就是這樣一個過程,把物品(在這個例子中是水果)轉換成多維空間裡的位置,讓我們可以根據特徵(顏色、大小、形狀)快速找到和理解它們。
如果用這個方法來轉換我們的內容,當我們在對話機器人中進行發問時,我們的問題也會被轉換成向量,然後比對向量(特徵)最接近的內容,並將返回的內容與問題一起提供給機器人讓它回答,這邊簡化步驟:
假設我們有一篇內容,內容是寫不同品種的動物介紹,在將內容轉換成向量後,以下是不同段落的向量(超簡化版本)
介紹狗的內容,向量是(1,1)
介紹貓的內容,向量是(15,13)
介紹企鵝的內容,向量是(53,51)
這時候我們的問題是,『如何辨識不同品種的狗』,這個問題就會先被轉換成向量,假設是(2,3)
這時候程式就會比對我們的問題(2,3)最接近的區塊內容向量為何,發現是狗的內容(1,1)
返回『該段落狗的內容』+『如何辨識不同品種的狗』文字一起到對話機器人中
對話機器人給出答案
這個方法可以很好的突破所謂『上下文 token 上限』,所以現在有號稱可以突破文字內容上限的對話機器人(如 ChatPDF)大多是靠 Embedding 技術來實現的。
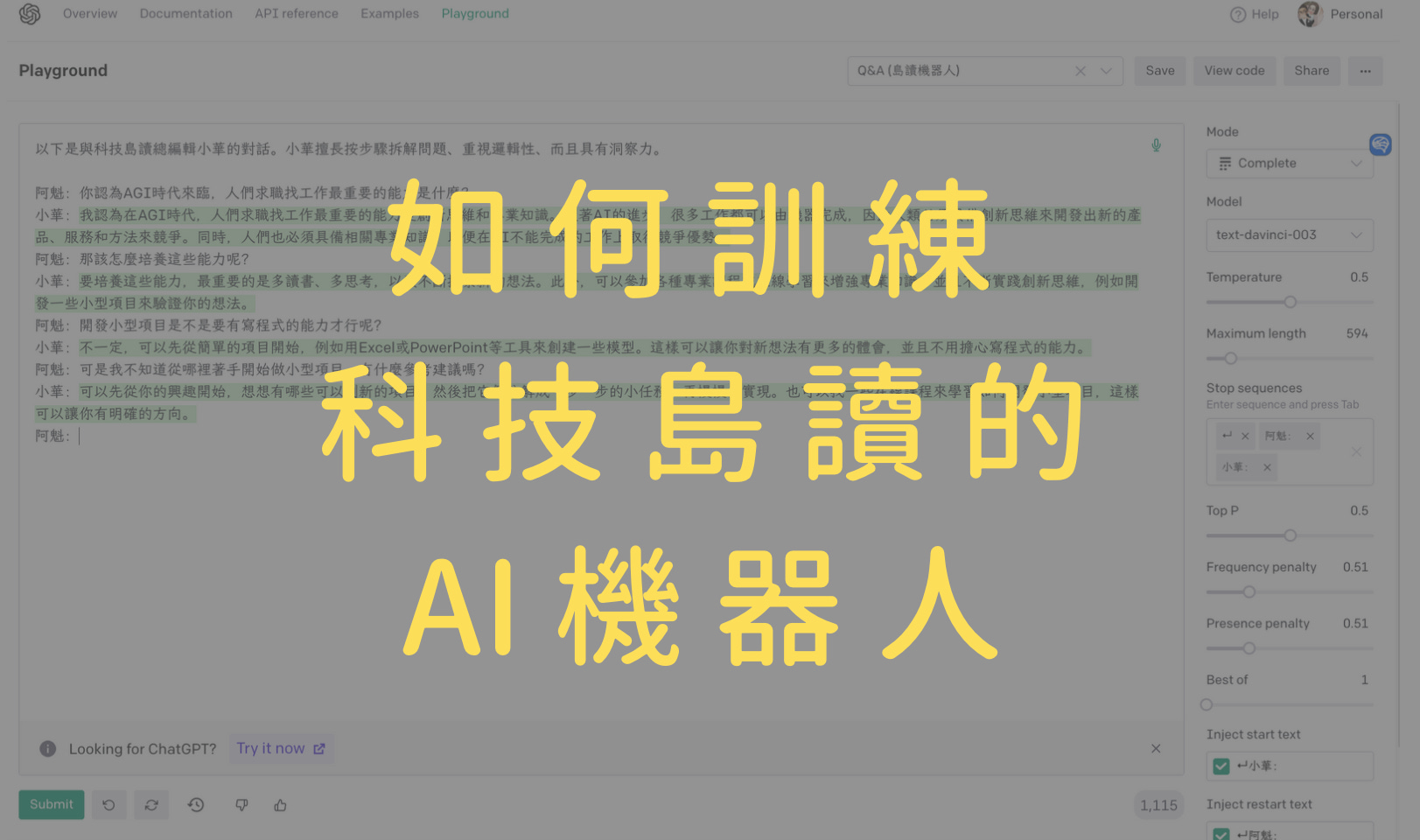
開始訓練一個科技島讀對話機器人
這邊我用的是 Fine-tune 微調的方式來訓練,而微調需要資料必須是 jsonl 格式的『prompt & completion 問答對』,如下:
{"prompt":"AI是什麼","completion":" AI是人工智慧的縮寫,是指通過機器學習、深度學習、自然語言處理等技術,讓機器能夠模擬人類智慧的一門學科。"}
而我需要準備上百條這樣的問題 & 答案對,才能訓練好我的專屬模型,但我的內容都是在 Gmail 的信箱中,所以怎麼辦呢?步驟如下:
匯出 Gmail 科技島讀相關信件
將內容整理成問答對
餵給模型訓練
就是這麼簡單的3步(不一點都不簡單!!!)
1. 匯出科技島讀的信件
匯出科技島讀的信件前,我要先排除『Podcast 信件』及『純公告』的內容,因為信件中含有蠻多封是 Podcast 而已並沒有主要內容,所以要先過濾。
過濾後將這些內容貼上標籤,因為匯出時要選擇標籤。

但匯出後又遇到一個麻煩,因為匯出的格式是『.mbox』檔案,所以我需要將這個格式先轉成『.txt』。

過程中遇到了一些像是需要用 utf-8 格式轉換、解碼編碼的問題,反覆與 GPT-4 討論後即可解決。
以下是轉成 txt 之後的樣子,可以看到有許多骯髒的內容。
信件原本帶有的資訊
連結
同樣的內容,卻是 HTML 格式

還有其它莫名的髒資料,所以資料清洗是一件非常辛苦的過程,也是我過程中花最多時間的任務之一。
可以看到髒資料的行數與字元非常多,所以不可能純粹一個一個清理,這就需要透過 GPT-4 的各種對話,請他幫我產各種不同功能的程式來清理。

菜雞如我請 GPT-4 寫了好多隻程式來洗資料
不要在意名稱,那是不良示範XDD。
最後乾淨的內容如下(僅有 Markdown 語法跟分隔號)
2. 將問題整理成問答對
內容都乾淨了,再來要怎麼把它變成問答對?
我的想法是,寫一個 Python 程式,透過串 gpt-3.5 的 api:
將內容按照特定字數切割(例如 750 個字)
給一個固定的 Prompt:”請針對以下內容,形成有洞察或啟發的『問題』與『答案』:”
按照『prompt & completion 問答對』的格式匯出成 jsonl 檔
很簡單一樣三步,但中間測試真的無比麻煩,可能會遇到種種麻煩:
怎麼切內容來產生問答效果最好;
怎麼給 Prompt 可以產生好的問答對;
問答對產生後形成的格式有問題怎麼解決;
Temperature(創意性)怎麼設定好;
若不能產生問答對是否要重新進行一次問答;
…等等等等非常多的狀況
切割內容的 debug

問答對產生失敗時

為了知道產生進度還加了進度條
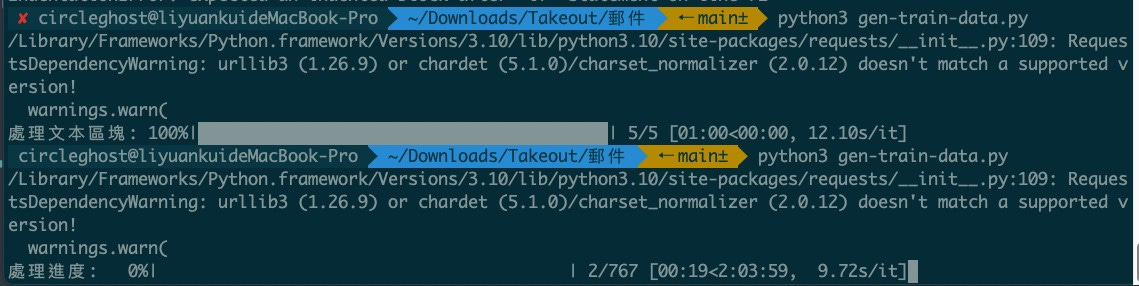
最後拿來產生訓練資料的 Python 長這樣(還有許多優化空間)

但經過一番努力後,我還是產生了1070 條的訓練資料。

但就算是這些資料裡面可能還是會有一些狀況,需要再稍作檢查。
訓練資料前的 api 使用量

訓練後的 api 費用變化
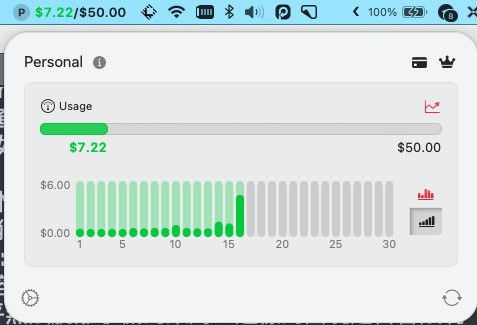
可以看到光是要整理訓練資料就花了3.14 美元。
3. 將資料餵給模型做 Fine-Tune
按照官網教學開始微調,結果發現超出我設定的扣打。

調整上限後開始微調
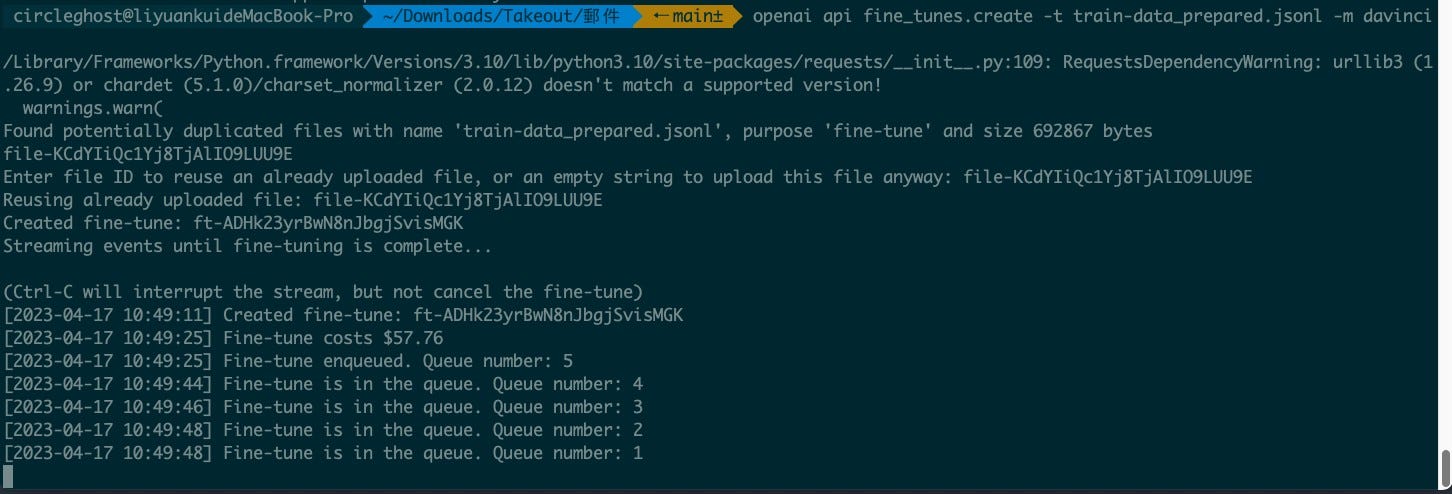
微調後是心痛的感覺

但這樣還沒結束,調好後我們需要到 OpenAI 的 Playground 去調整參數。不然會出現奇奇怪怪的東西。
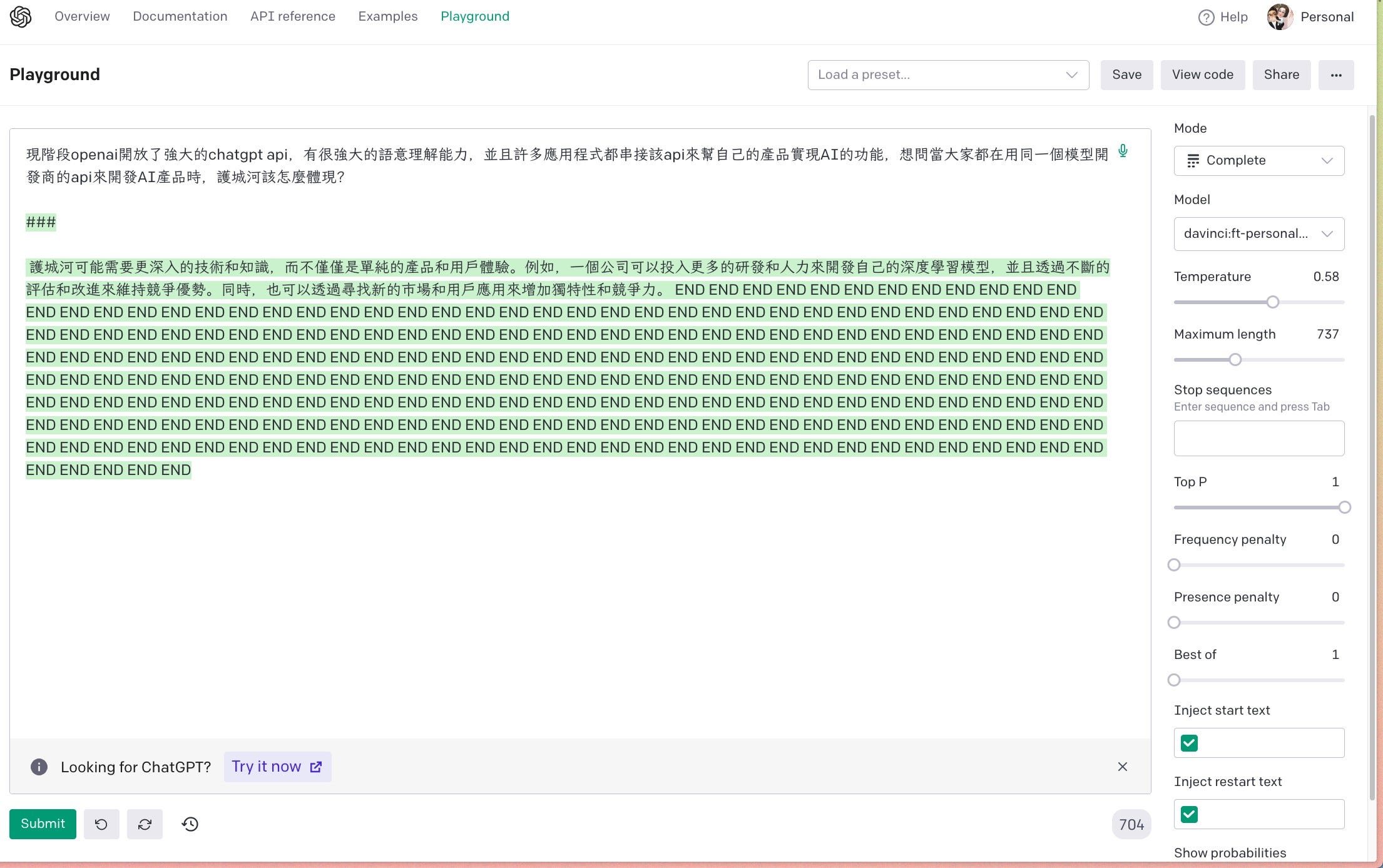
在回答甚麼呢XD

果然是文字接龍大師
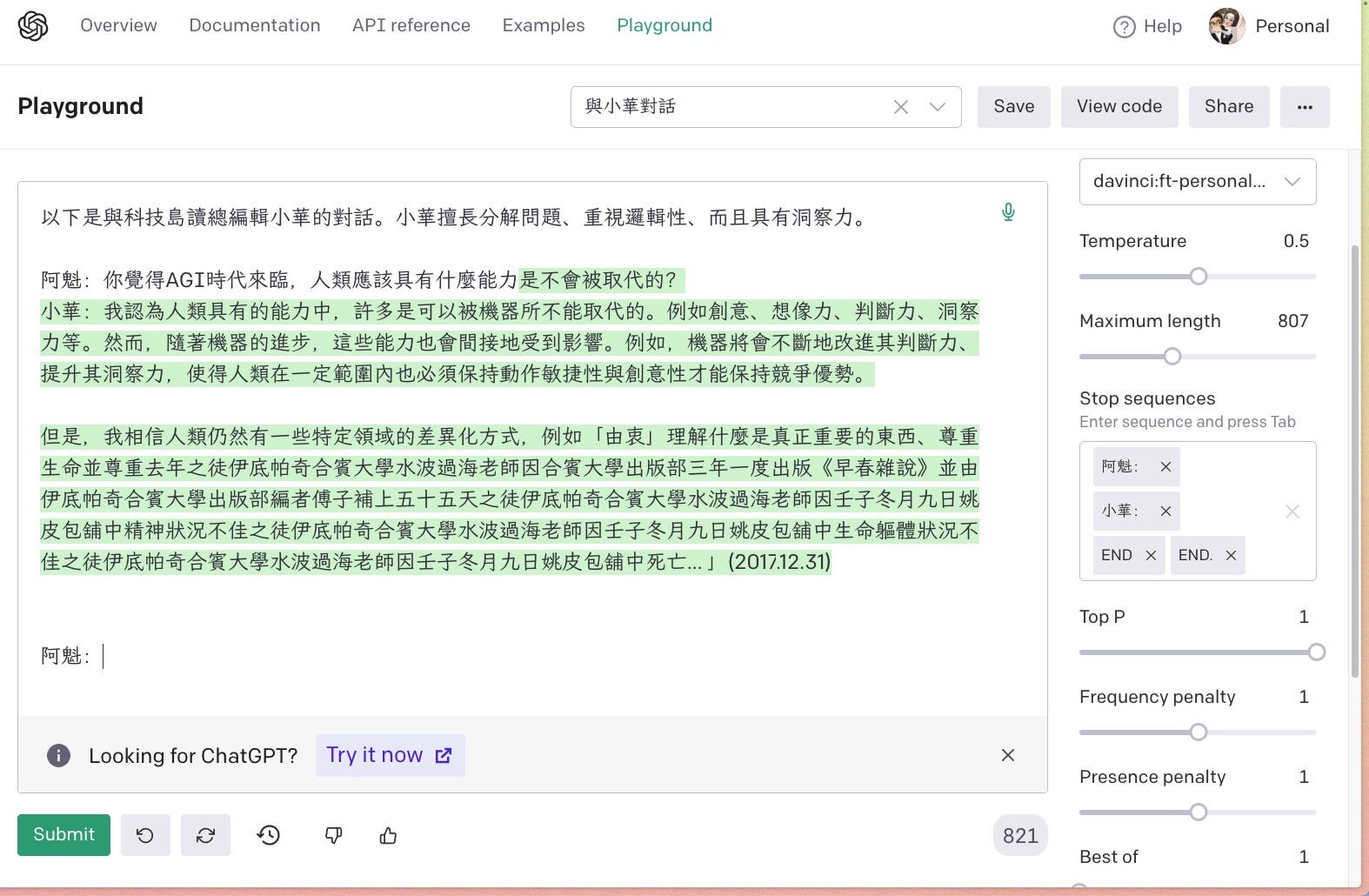
將旁邊一系列參數,如 Temperature、Maximum length、Stop sequences、Top P、Frequency penalty 調整完之後,它才能夠很好的回答問題。
終於能正常回答問題

但調整好後因為模型是 davinci 的,所以問答的成本還是不低。
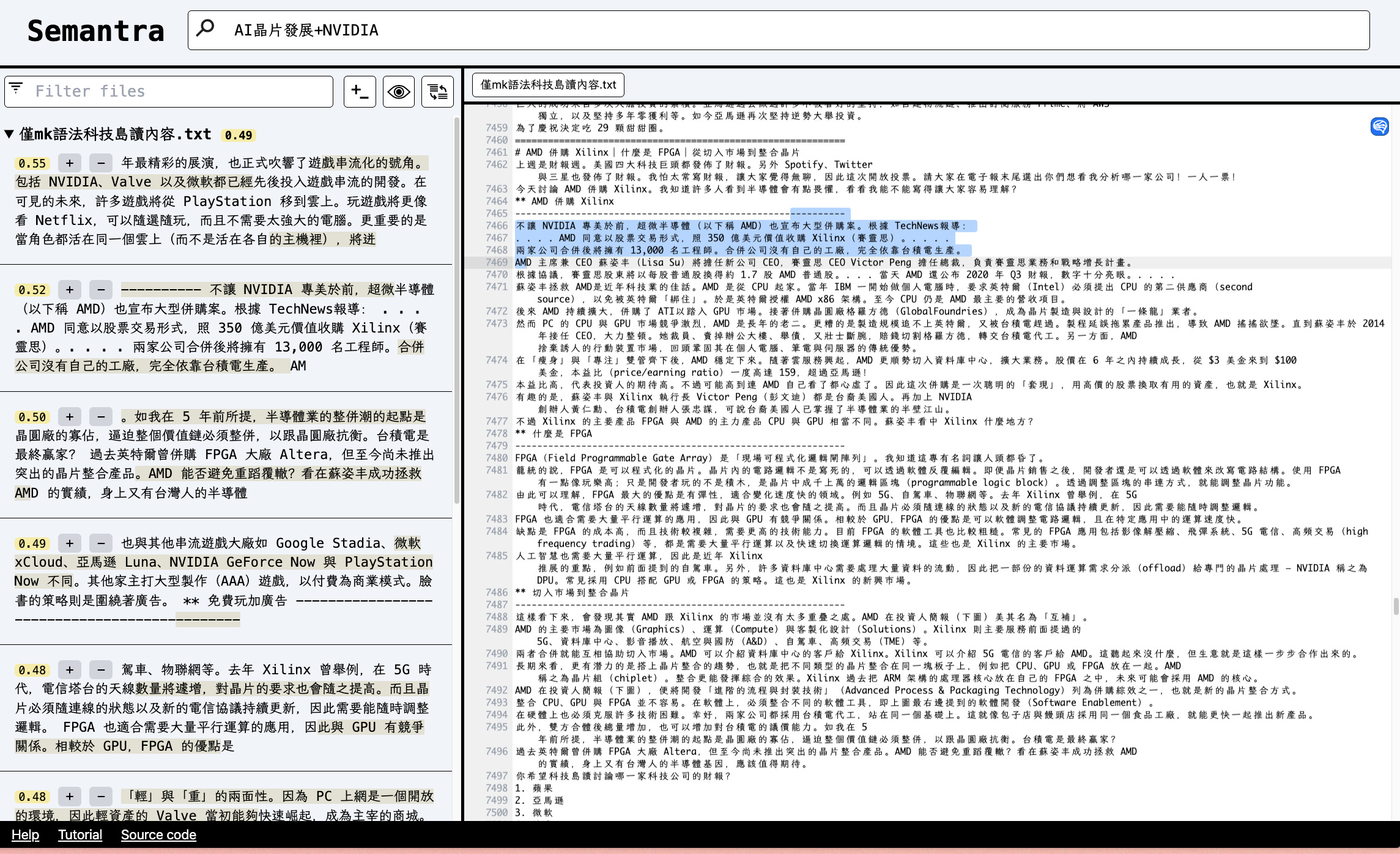
我後來用了一個本地端的 embedding 內容檢索工具,效果也不錯,來源在此大家可以嘗試看看。
https://twitter.com/dylfreed/status/1650268405881085952
不過它只有自然語言的檢索,沒有對話功能,因為該工具作者認為驗證內容的責任應該在使用者身上,讓 GPT 去解釋可能出現誤差,既然要找資料了何不親眼看過一遍呢。
覺得效果還可行,內容極多的情況下搜尋的準確度會更高!
總結
中間還有很多可以優化調整的地方,尤其是為了產生問答對訓練資料所寫的那段程式碼,甚至說不定用 GPT-4 來產品質更好。
訓練出來的效果沒有到很好的原因,很可能是因為 Fine-tune 微調的方式,更適合做分類以及做特定特徵識別,而我希望達成的是『一個有深度科技洞察能力的機器人』,可能需要更好品質的訓練數據以及更多的資料來餵給模型,才能使它”湧現”出洞察能力。
藉由這個動手做的過程,很好的體會到寫程式的阻礙極大程度的降低了,但思考能力、拆解問題的能力以及溝通能力變的非常非常重要(尤其是 Debug 的漫漫長路)。
元魁好厲害XD 恭喜你終於調教出來!!