


禮拜六在臉書上簡單分享自己抓內容當知識庫的方法,沒想到大家迴響這麼熱烈,教學這就來了。
如果大家覺得實作難的話,也能與我聯繫協助製作知識庫,我會報價給你的,希望可以幫到大家!
聯繫信箱:circleghost0723@gmail.com
不過這邊還是要特別提醒幾點:
該實作還是需要一點程式基礎搭配,不然上手還是有一定難度,但我盡量寫清楚。
每個步驟的方法都不是唯一,讀者們需要根據自己想爬的網站調整方法。
GPTs 需要有 ChatGPT Plus 的會員,所以沒有 Plus 會員的讀者目前暫時無法實作。
該實作方法僅試用於網站頁面少於 500 頁的頁面,超過了需要另尋工具,但思路可供參考。
如果你還不知道 GPTs 是什麼,或是想理解一點基本設定,推薦看 Axton 的這隻介紹影片:
正文開始!
0. thinking….
做之前要先思考分析,然後畫出路徑,才能在解決問題時少費點力,先定義目標:
爬取特定網域上某些文章頁面,並儲存成 txt 格式。
首先,分析網站上的網址
提取網址,並解析頁面的主要內容
逐一爬取並轉成目標格式
基本上這 3 步就能完成所有事(但沒這麼簡單!)
1. 分析網站上的網址
▎網站地圖找所有頁面
如果今天要爬取網頁的所有內容時,有一個很方便的東西叫做網站地圖『sitemap』,通常只要在網址後面加入 /sitemap.xml 就能看見。
例如:https://pmthinking.com/sitemap.xml

但並非所有網站都會設定網站地圖,大部分內容管理平台如 WordPress 不出意外的話都會有。
▎尖叫蛙:頁面爬取神器
那如果出意外的話呢,可以用另一個軟體叫做尖叫蛙(Screaming Frog)。
這是一款 SEO 顧問公司常用的工具,它可以用來爬取網站所有相關的 SEO 資訊,本質上它就是一款爬蟲工具,只是爬的是 SEO 相關資訊。

下載連結:https://www.screamingfrog.co.uk/seo-spider/
點擊 Download 然後下載對應電腦版本的”尖叫蛙”。
打開軟體後,在該位置輸入頁面首頁,尖叫蛙就會開始爬取整個網站。
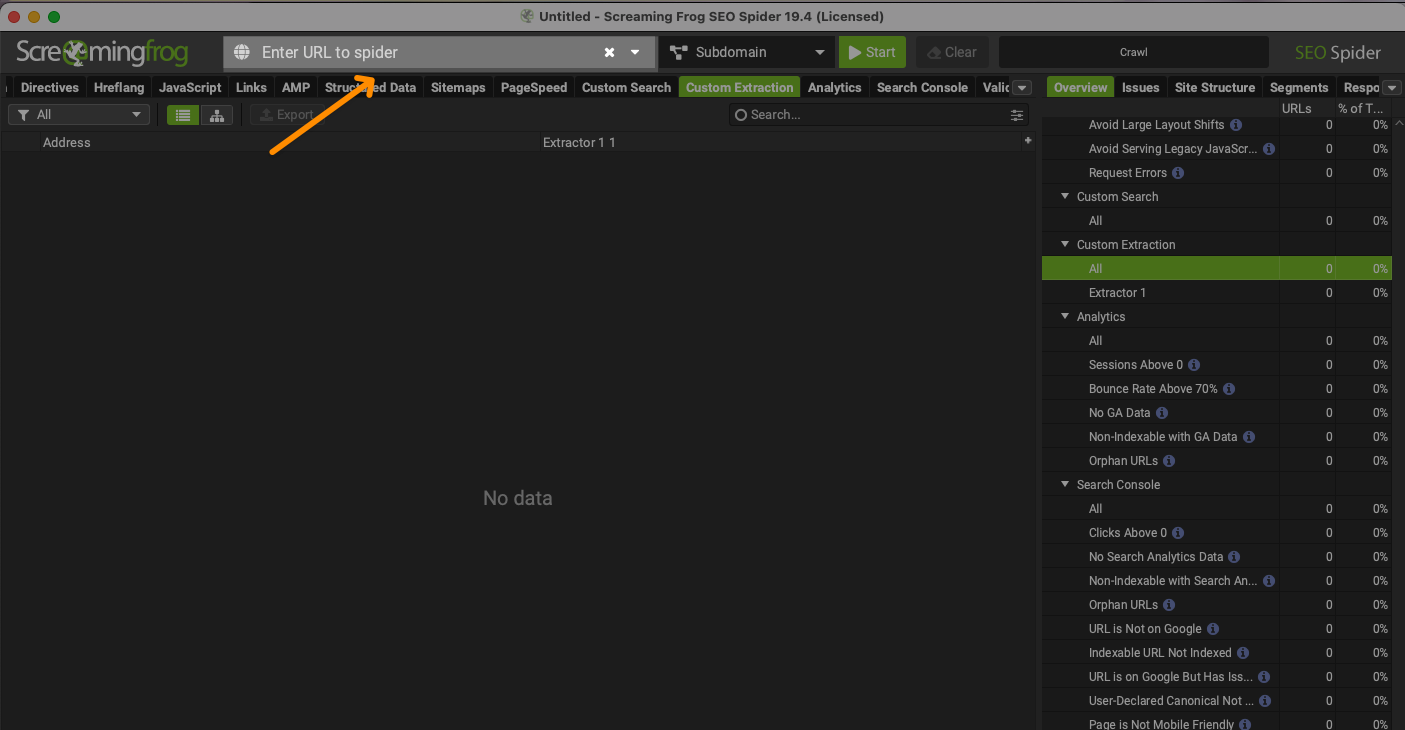
免費版每次有 500 個 URL 的限額,所以該方法僅供網站內容沒有超過 500 頁的話可以用該方法。

可以無限次使用,免費版限制的是『每次爬取的 URL 上限』,所以一開始可以先把網站首頁輸入嘗試。

點擊 Page Titles,然後按 Export 可以匯出這些頁面及連結。
▎觀察網址結構長怎樣
不管網站有沒有爬取完,或是只爬取一部分,我們都能知道『網址結構』。
因為我們可以請 ChatGPT 協助處理網址,舉例來說,今天我要抓 Google 關於 SEO 的文件,我發現:
重要內容的路徑中均包含 /docs/ 這個路徑
中文語系帶有參數 ?hl=zh-tw
2. 提取網址,並解析頁面的主要內容
▎ChatGPT 清理網址資料
這時候我們就能把 Sitemap.xml 下載下來(或是剛剛從尖叫青蛙下載的網址)交給 ChatGPT 來篩選我們的內容網址,強烈建議先下載下來,再上傳給 ChatGPT。
只要在 Sitemap.xml 的頁面,點擊『右鍵 > 另存為』然後按儲存即可。
舉例來說,這是關於 Google 官方 SEO 文件的 Sitemap:https://developers.google.com/search/sitemap.xml

但網址非常亂,如果不事先處理後面再提取時效率就會非常低下。
可以看到我這個 Sitemap 檔案非常大,到 44 MB

這時候選擇 GPTs 的 Data Analysis,然後點擊迴紋針上傳 Sitemap 。
請它處理特定路徑或是參數的網址,我這邊用的 prompt 是:
能否幫我處理規定的 Sitemap.xml,只提取 /docs/ 路徑的網址,並且要包含『?hl=zh-tw』這個參數的網址,最後整理成 txt 檔案供我下載。
瞬間我們要的網址就處理好了。

如果上一步尖叫蛙就已經將網頁都爬取完了,或是本來就知道內容網址的規律,也可以直接跳到這一步,請 ChatGPT 直接把目標網址解析出來。
▎找到內容上的 CSS 選擇器
CSS 選擇器聽起來很專業,用途就是讓我們可以定位網頁的內容在哪裡,影片在此。
3. 轉換目標網址內容行成 Markdown 語法的 txt 檔案
原本這一步要結合尖叫蛙,結果我發現需要用到尖叫蛙的付費版本,我臨時用 streamlit 幫大家寫了一個線上程式,只要你把網址整理好給我,就能幫你轉換成 markdown 語法的 txt 檔案。
工具:https://turntomd.streamlit.app/

首先,含有網址的 txt 檔案必須僅包含網址,且一行一個網址。
然後按照剛剛教學的方式複製 CSS 選擇器並貼上。
然後程式會幫你解析網頁內容並產生知識庫,而且會將可能錯誤的網址,以及網頁中沒有帶有該 CSS 選擇器的頁面篩選出來讓你知道。

至此按下下載就能擁有自己的知識庫了。
但是還是要溫馨提醒:
有些頁面是 JS 渲染的話,可能導致尖叫蛙爬取失敗,或是工具轉換失敗。
網頁如果沒有 Sitemap、頁面數量龐大、或是網址沒有固定規律可能都會在實作上有困難。
達成目標可以有很多方法,過程中有很多節點讓大家可以參考並換思路執行,所以不必拘泥一定要用我的方法,能達成目標就是好方法。
如果大家在實作上還是感到困難,需要知識倉鼠代為製作知識庫的話請聯繫信箱,我會再報價給你。
聯繫信箱:circleghost0723@gmail.com
乾貨滿滿!